Web Focus: WebWatching UK Universities and Colleges
About WebWatch
WebWatch is a one year project funded by the British Library Research and Innovation Centre (BLRIC) [1]. The main aim of WebWatch is to develop and use robot software to analyse the use of web technologies with various UK communities and to report on the findings to various interested communities. Other aims of WebWatch include:
- Evaluation of robot technologies and making recommendations on appropriate technologies.
- Analysis of the results obtained, and liaising with the relevant communities in interpreting the analyses and making recommendations.
- Working with the international web robot communities.
- Analysing other related resources, such as server log files.
WebWatch Trawls
UK Public Libraries
The WebWatch robot was launched on the evening of Wednesday, 15th October 1997 - the day of the launch of the LIC’s ‘New Library: The People’s Network’ report [2]. The robot trawled UK Public Library websites, as defined in the Harden’s list [3]. The aim of this initial trawl was to audit the size of public library websites on the day of the launch of the New Library report.
UK Universities and Colleges Home Pages
The second WebWatch trawl took place on the evening of Friday 24th October. This time the robot analysed UK Higher Education Universities and Colleges home pages (i.e. the institutional entry point), as defined by the HESA list [4].
The WebWatch robot stored the following information for subsequent analysis:
- HTML elements
- A count of all HTML elements used in the institutional entry page and details of element attributes. This includes:
- Metadata Details
- Use of the <META> element and of the type of metadata used.
- Link Details
- A count of the numbers of links and details of the destinations of the links.
- Image Details
- A count of the numbers of inline images and details of the <IMG> attribute values (e.g. WIDTH, HREF, etc).
- Script Details
- A count of the number of client-side scripts.
- Header Information
- HTTP header information, including:
- Server Software
- The name and version of the server software used.
- File Size
- The size of the institutional HTML entry page.
- Modification Date
- The modification date of the institutional entry page.
Figure 1 illustrates the raw data file.
Gatherer-Time{24}: Fri Oct 24 19:21:00 1997 File-Size{4}: 2323 CRC{9}: 200 (OK) Message{3}: OKD Date{20}: Fri, 24 Oct 1997 18 Server{13}: Apache/1.1.3 … Type{4}: HTML total-count{2}: 69 p-count{1}: 3 a-count{2}: 15 center-count{1}: 1 b-count{1}: 5 title-count{1}: 1 head-count{1}: 1 br-count{2}: 17 .. img-60-attrib{61}: width=13|src=../gifs/redgem.gif|height=13|alt=*|nosave=nosave a-48-attrib{30}: href=/www/schools/schools.html …
Figure 1 - Portion of the Raw Data Collected by the WebWatch Robot
The first part of the data file contains the HTTP header information. The second part contains a count of all HTML elements found in the home page. The final part contains the attribute values for all HTML elements.
Analysis of UK Universities and Colleges Home Pages
A total of 164 institutions were included in the input file. The WebWatch robot successfully trawled 158 institutions. Six institutional home pages could not be accessed, due to server problems, network problems or errors in the input data file.
Page Size
The average size of the HTML page is 3.67 Kb. Figure 2 gives a histogram of file sizes.
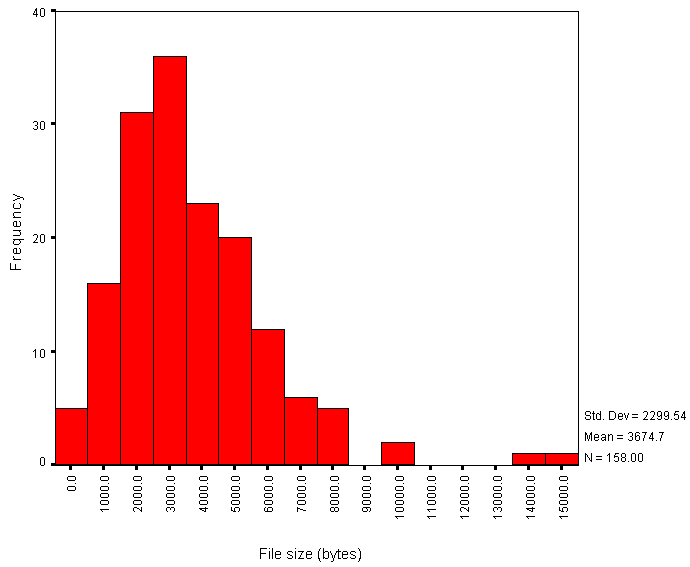
Figure 2 - Histogram of HTML File Sizes versus Frequency
It should be noted that the file sizes do not include the sizes of inline or background images. This histogram therefore does not indicate the total size of the files to be downloaded.
HTML Element Usage
The average number of HTML elements on institutional HTML pages is 80. Figure 3 gives a histogram of the numbers of HTML elements.
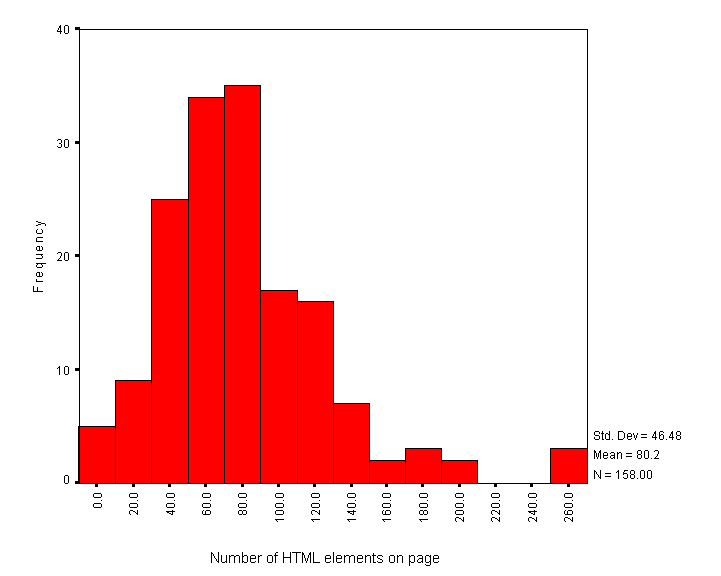
Figure 3 - Histogram of Numbers of HTML Elements versus Frequency
Note that this data is based on counts of HTML start tags. It will omit implied element usage (such as text following a head element which have an implied paragraph start tag).
Also note that in a web document consisting of several frames the numbers of HTML start tags will only cover the tags included in the page containing the information about the frames, and not the documents included in the frames.
The most frequently used HTML element in the sample was the <A> element. Figure 4 gives a summary of the five most popular HTML elements.
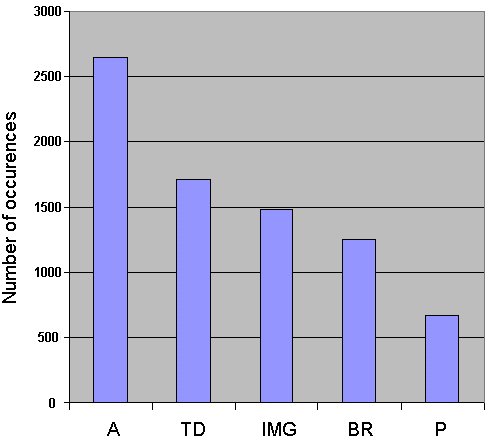
Figure 4 - The Five Most Widely Used HTML Elements
Examination of Particular HTML Elements
Usage of a number of particular HTML elements was examined in greater detail.
- A total of 104 out of the 158 institutions surveyed (66%) made use of the <TABLE> element.
- A total of 12 out of the 158 institutions surveyed (7.6%) made use of the <FRAME> element.
- A total of 11 out of the 158 institutions surveyed (7%) made use of the <SCRIPT> element. Note that does not include use of Javascript event handlers.
- A total of 16 out of the 158 institutions surveyed (10.1%) made use of client-side maps.
- One institution made a single use of an inline style defined in the HTML BODY and one institution made a single use of an inline style defined in the HTML HEAD.
In addition it was observed that there were no occurrences of Java in institutional home pages. There was one occurrence of a page with background sound.
A number of metadata attributes were analysed, including:
- The GENERATOR attribute which defines the tool used to create the HTML page. This attribute is created by software such as Microsoft FrontPage and Netscape Gold.
- The NAME=“Description” and NAME=“Keywords” attributes which are used by the Alta Vista search engine.
- PICS metadata.
- Dublin Core metadata.
- The REFRESH attribute, used to refresh pages and to automatically load other pages.
A histogram of use of these <META> element attributes is shown in Figure 5.
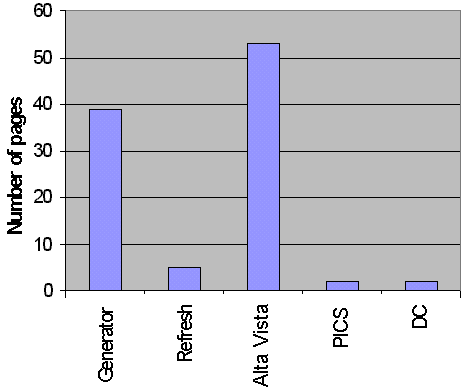
Figure 5 - Histogram of META Attributes versus Frequency
Software used to create the home page included various Netscape authoring software (15 occurrences, 9.5%), Microsoft Front Page (12 occurrences, 7.6%), Internet Assistant for Word (3 occurrences, 1.9%), Claris HomePage (3 occurrences, 1.9%) and PageMill (1 occurrence, 0.6%).
The “REFRESH” attribute was used to refresh the page (or send the user to another page) in 5 institution home pages. Of these, two used a refresh time of 0 seconds, one of 8 seconds, one of 10 seconds and one of 600 seconds.
Dublin Core metadata was used in two institutions.
PICS content filtering metadata was used in two institutions.
Numbers of Links
The average number of links on institutional HTML pages is 17. Figure 6 gives a histogram of the number of links.
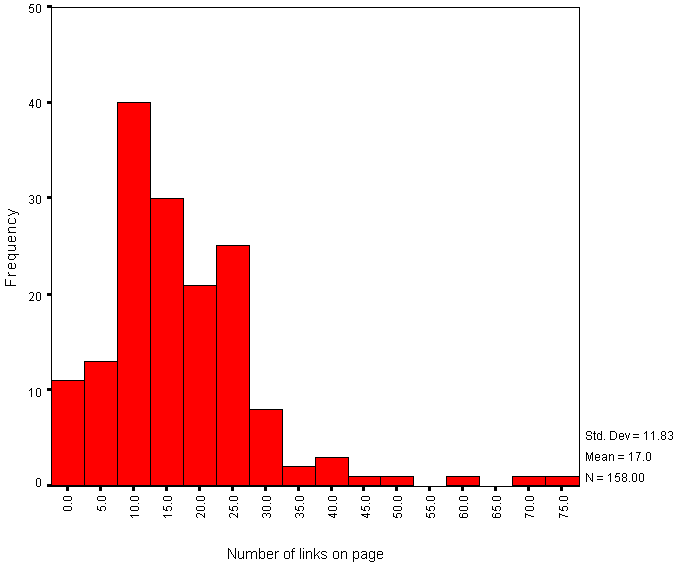
Figure 6 - Histogram of Numbers of Links versus Frequency
This histogram includes links contained in the following HTML elements: <A>, <APPLET>, <AREA>, <EMBED>, <FRAME>, <BASE>, <IFRAME>, <IMAGE>, <LINK>, <MAP> and <OBJECT>. It does not, however, include links used in server-side active maps.
Note that the histogram shows the total number of links - in some cases links may be duplicated, such as links provided by client side maps and repeated as simple hypertext links.
Also note that the WebWatch robot does not obey the HTTP REFRESH method, and so the numbers of links for the small numbers of institutions which make use of REFRESH will be underestimated.
The WebWatch robot retrieves the initial HTML file specified in the input file. If this file contains a FRAMESET element the robot will only analyse the data contained in the original file, and will not retrieve the files included in the frames. This means that the numbers of links for the 12 institutions which uses frames will be underestimated.
Server Usage
The most popular server software was Apache, used by 49 institutions (31%). Figure 7 gives a chart of HTTP server software usage.
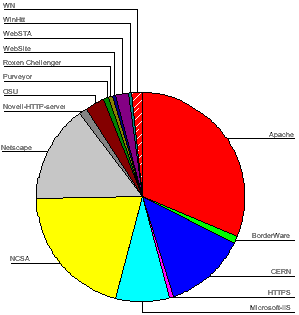
Figure 7 - HTTP Server Software Usage
Interpretation of Results
The results summarised in this article should be of interest to institutional web teams, as they will help institutions to compare their web site with others in the community. Institutions face the conflicting pressures of ensuring that the resources can be accessed by a wide community, using a variety of different browsers on a variety of platforms, and making their institutional entry point attractive and distinctive from other institutions. The analysis provides useful information on how the community is facing up to these conflicting pressures.
Institutional Home Pages
The analysis of institutional web pages shows a normal distribution for the size of the HTML page, with two significant outliers (Figure 2). On examination of these two pages, it is the use of Dublin Core metadata in one case, and extensive use of Javascript in the other, which appear to add to the size of the HTML file. The size of the HTML file is not likely, however, to be indicative of the time needed to download the page, since this is likely to be dominated by the size of images, which were not analysed in this survey.
The analysis of the number of HTML elements also shows a normal distribution with three outliers. In each of these cases tables were used extensively to provide control over the appearance of the page.
The chart of the most popular HTML elements (Figure 4) shows the <A> (anchor) element to be most widely used, with 2,641 occurrences (an average of over 16 hypertext links per institutional home page). The next most widely used element was <TD> (table data), which is indicative of the popularity of tables. The third most widely used element was <IMG>, with almost 1,500 occurrences (an average of 9.4 images per institutional home page).
Examination of use of the <META NAME=“GENERATOR”> element attribute shows that Netscape and Microsoft are battling for the most widely used authoring tool. However it should be noted that the GENERATOR attribute is only used in 23% of the home pages, perhaps indicating that the majority of home pages are produced by other software packages or by hand.
The REFRESH attribute is used in 5 institutions to refresh a page after a period, or to send the user to another page. It is used to display an eye-catching page, and then take the user to the main institutional menu page. It should be noted that since the WebWatch robot does not make use of this attribute, the data collected by the robot will reflect the HTML page containing the REFRESH attribute and not the final page viewed by the end user.
Over 50 institutions make use of the metadata popularised by the Alta Vista search engine. However it is perhaps surprising that more institutions do not provide such information.
Clearly both PICS and Dublin Core metadata have not yet taken off within the community, with only two institutions providing PICS information and two providing Dublin Core metadata.
The histogram of numbers of links (Figure 6) shows a normal distribution, with a number of outliers. Examination of the outliers shows that a small number of institutions provide large numbers of links to their resources, whereas most institutions have a more minimalist set of links.
Almost two thirds of the sites surveyed made use of tables, indicating that table support is taken as standard by the majority of sites. Only 7.6% of the sites made use of frames, indicating, perhaps, that institutions felt that the level of browser support of frames was too low.
Little use is made of client-side scripting languages, with only 7% of the sites made use of JavaScript in their institutional entry page. No sites made use of ActiveX. Only 10% of the sites made use of client side maps in their institutional entry page.
Only two institutions have made use of style sheets, and even this use is minimal.
Institutional Server Software
The analysis of server software shows that, as may have been expected, the Apache software is the most popular. This is followed by the NCSA and CERN software - which were the original HTTP servers used by most institutions. It is perhaps surprising that these servers are still so popular, as NCSA and CERN are no longer significant players in the web software development circles and the CERN server, in particular, suffers from performance problems.
Netscape servers are popular, with an even split of 10 apiece between the Netscape Communications and Enterprise servers, and 3 occurrences of the FastTrack server.
Microsoft lags behind Netscape, with 12 institutions using the Internet-Information-Server software, and, surprisingly, one using the MS Windows 95 Personal Web Server.
Other server software products are used by one or two institutions.
WebWatch Futures
Further Analyses Of UK HEIs
The initial analysis of the data has provided some interesting statistics, and also indicated areas in which additional information is required. It is planned to modified the WebWatch robot slightly in order to enable inline images and background images to be analysed.
Additional analyses will be carried out including:
- A detailed analysis of hypertext links to build a profile of hypertext linking from institutional home pages.
- Analysis of HTML conformance.
- Analysis of broken links on institutional home pages.
- Analysis of modification dates of institutional home pages.
- Analysis of client-side scripts.
- Analysis of documents using frames.
Working With Other Communities
An important aspect of the WebWatch project is liaison with various communities. We intend to give presentations of our findings at a number of conferences, workshops and seminars. In addition, we would like to work closely with particular communities, in identifying resources to monitor, interpreting the results and making recommendations to relevant bodies. If you would be interested in working with the WebWatch project, please contact Brian Kelly (email B.Kelly@ukoln.ac.uk or phone 01225 323943).
References
- BLRIC,
http://www.bl.uk/services/ric/ - New Library: The People’s Network,
http://www.ukoln.ac.uk/services/lic/newlibrary/ - UK Public Libraries,
http://dspace.dial.pipex.com/town/square/ac940/ukpublib.html - HESA List of Higher Education Universities and Colleges,
http://www.hesa.ac.uk/hesect/he_inst.htm
Acknowledgements
The WebWatch robot software is a version of the Harvest software suite which was modified by Ian Peacock. Ian, who was appointed to the WebWatch post on 28th August 1997, was also responsible for running the robot software, processing the data and producing the statistics and graphs. Ian can be contacted at the email address I.Peacock@ukoln.ac.uk
Author Details
Brian KellyUK Web Focus,
Email: B.Kelly@ukoln.ac.uk
UKOLN Web Site: http://www.ukoln.ac.uk/
Tel: 01225 323943
Address: UKOLN, University of Bath, Bath, BA2 7AY