The ExamNet Project at De Montfort University
Abstract
The ExamNet project offers access to past De Montfort University examination papers in electronic form. Exam papers from the past three semesters have been scanned and indexed and are available to all students, members of staff and researchers within De Montfort University via the World Wide Web. This article discusses why and how the system was implemented and offers guidelines for library and information systems developers at other educational institutions who may be considering setting up a similar service.
Motivation
The key motiivating factor for setting up an electronic exam system was to:
- reduce the time spend by librarians dealing with exam paper queries
- avoid the loss or damage of exam papers
- improve access to the exam papers
- provide powerful easy to use search facilities
Previous to the ExamNet project being set up, the library received paper versions of past examination papers from the Exam Office as a continuous stream as opposed to a bulk transaction and then processed them. This process involved cataloguing and indexing the papers on a stand alone computer, printing the complete record database and then placing a copy at a suitable location in the library.
The whole system from exam writing to archiving could take several months and several steps, each step introducing the potential for errors and misfiling. It was therefore clearly advantageous for the university library to develop an electronic approach that would, where possible, automate these procedures. It was also desirable to have a networked version to allow easy access for users across the various DMU sites.
Each School and department within the university has its own favoured electronic format(s). Within the School of Computer Science, for example, Word6 for Windows, Word7 for Win95, AMI-Pro, LaTeX and Mac Word 2 are all used. At a rough estimate about 50% of exams are delivered to the school office in electronic format. The conversion of formats to an acceptable standard was regarded as being inappropriate due to time and effort. A typical conversion from AMI-PRO to Adobe Postscript involves the following steps:
- Load from School server (this presently via floppy)
- Load into Ami Pro on a networked PC
- Select print option and print to the SiMX driver
- Save the file as filename.prn
- Exit AmiPro and transfer the file to a UNIX server
- Ensure Netscape client has a PostScript viewer
- Helper Application (ROPS is a reasonable one
Clearly this was unacceptable.
The Library recognised that the only feasible solution to the problem was to use scanning and Optical Character Recognition software in conjunction with a local database to register parametric data that could be used at a later date for refined searching.
Scanning and OCR
Experiments carried out in Centre for Educational Technology on scanning and OCRing showed that there were two reasonable packages available. These were OmniPage and Adobe Capture.
Both packages were available for PCs and Macs and both produced very good results on the test samples provided. These test samples included text (including handwritten), tables, mathematics, images and symbols.
OmniPro 7 can be configured in a number of ways that include :
- Scanning only - to produce TIFF Gp 4 FAX
- Manual - Scan, Zoning, Text and save
- Auto - Scan, Zoning, Text and save
- Batch - Images may be OCRed in batch with manual intervention.
Images may be scanned at a wide range of resolutions and saved in a variety of formats.
The scanning of each page takes between 30 and 60 seconds.
The Adobe system also produced very good results and used the widely accepted Portable Document Format that is favoured by many publishers. The Adobe Capture system became the preferred option.
Points for implementors :
- Handwriting is NOT recommended as the number of errors detected proved to be difficult to cope with.
- University stamps that are superimposed on the paper confuse the OCR package. Version without stamps were thus made available.
- If papers include a lot of images then manual intervention may be required to define zonal regions.
- The quality should be good enough for the system to at least recover enough information for metadata selection.
The system
The figure below shows a schematic diagram of the components with the ExamNet system. The major sub-systems are Scanning, Database WWW server and CGI search.
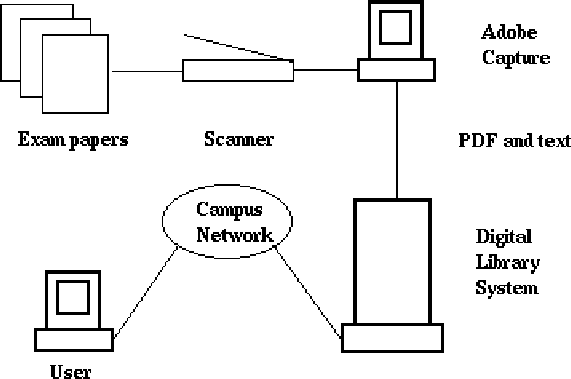
Scanning
A collection system was set up in the library short loans section that comprised a high performance PC, a scanner and a high volume portable disk drive (Zip). Instructions for the use of this system were issued and made available to library staff who were on duty at the short loans section. These instructions accompanied a log book in which a record was kept of what documents have been scanned, by whom and when.
At the end of each day (approx.) files are downloaded from the PC to the Zip Drive in compressed form. The Zip drive is then removed from the library and brought to the Digital Library office where the scanned files are loaded onto another PC for proofing. This step was eventually eliminated when the Library PC was fully networked and files could be transfered via FTP.
Each file needs to be looked at individually to ensure that no two pages have been scanned under the same file name. At this point any misspellings of filenames would also be rectified.
The next step was to run each scanned image through the TextBridge OCR package. To check each scanned file for separate images within the scan and block/zone them accordingly. However, it should be noted that if images such as tables appear in the middle of text, once saved as HTML, the image is always saved as a JPEG at the end of the file. Once the images have been OCR’d they need to be saved as (HTML) files. The original scanned papers are in PDF.
The files were then copied to the UNIX server, where they were sorted into directories via a Perl script. Originally PDF’s were generated by importing scanned TIF files in Acrobat Exchange and then using the Capture plug-in to OCR the text. However, this process had to be done manually (i.e. one Exam at a time) and was extremely time consuming, as well as monopolising the resources of the computer being used for this purpose. In order to accelerate the process, the full version of Adobe Capture was purchased. The object being to batch the existing TIF’s and therefore eliminate the need for individual processing. However, the Capture program was unable to accommodate the existing file structure containing the TIF’s. Fortunately, Capture did include a standard API (Application Programmers Interface) to access Capture’s OLE capabilities.
This feature allowed our placement student to re-program the Capture OLE server in order to accommodate our needs.
This was achieved through the following steps:
- Files are renamed dynamically to accommodate Capture’s insistence on files being inserted in alpha-numerical order;
- Folders containing TIF’s were traversed beforehand to detect for possible missing TIF files. The program decides which TIF’s should be contained within each folder be deriving their names from the folder name and the number of TIF’s contained within it;
- Logs errors to an output report file, as Capture’s default action is to halt the process. The amended program overrides this default setting allowing the process to continue and the user to check the resulting output file for errors at a more convenient time.
Once the amended program had been tested, it was then necessary to download the existing TIF files from storage on the main Digital Library System (DLS) to the PC in order to run the new Capture OLE. This process was hampered by problems encountered when FTP’ing files from the DLS to the PC. This was due to fact that when files were being FTP’d, space on the DLS would be claimed in order to allow the files to be copied, when the existing space considerations were exhausted, file copying would halt. It was therefore necessary to ‘push’ rather than ‘pull’ the existing files from the DLS to the PC. This was achieved by the writing of a script to copy the files from the DLS to a DEC workstation and then retrieve the files via FTP from the workstation. The reason for this copying to an interim machine was due to space considerations on the PC.
Finally the Capture program was run on the files producing PDF and text files on an overnight basis in order to maximise resources on the PC during the day. The resulting PDF and text files are then available for use on the Digital Library System.
Points for implementors :
- Scanning rate is approximately 6 exams per hour,
- Average exam has 10 pages,
- There are 4-5 hours of scanning per day,
- 800 exam papers will take roughly 26 days or five weeks.
The database
The project co-ordinator maintained a record of the scanned exam papers within a Microsoft Access database. There was, at the time, no method available to connect the scanning process to this database and so regular cross check reports were required to ensure the Access database did not get out of synchronisation with the information held on the Digital Library System.
The interface to Access was programmed via a support specialist who also ensured that exported databases would be produced with an ‘’ as the field deliminator. This latter step was necessary in order that the DLS Perl script could handle complicated titles and codes, as the ‘’ character was not used elsewhere.
Once the data was entered in the database it was exported to a text file which was transfered to the DLS. This transfer occurred after cross checking and after new batches of scans had been recorded.
The WWW server
The Digital Library System at De Montfort includes several large scale World Wide Web servers, one of which is for the main DMU library. The ExamNet system was integrated into the library pages as part of the electronic collections section.
The main advantages of the DLS are that is is has a high storage capacity, it is a high performance machine with a 256 Megabyte RAM, and is on a fast Ethernet network that operates at 100MB/sec. These features are desirable when offering a system to a large number of potential users that may be distributed over several locations and ensures a reasonable response times.
The CGI search
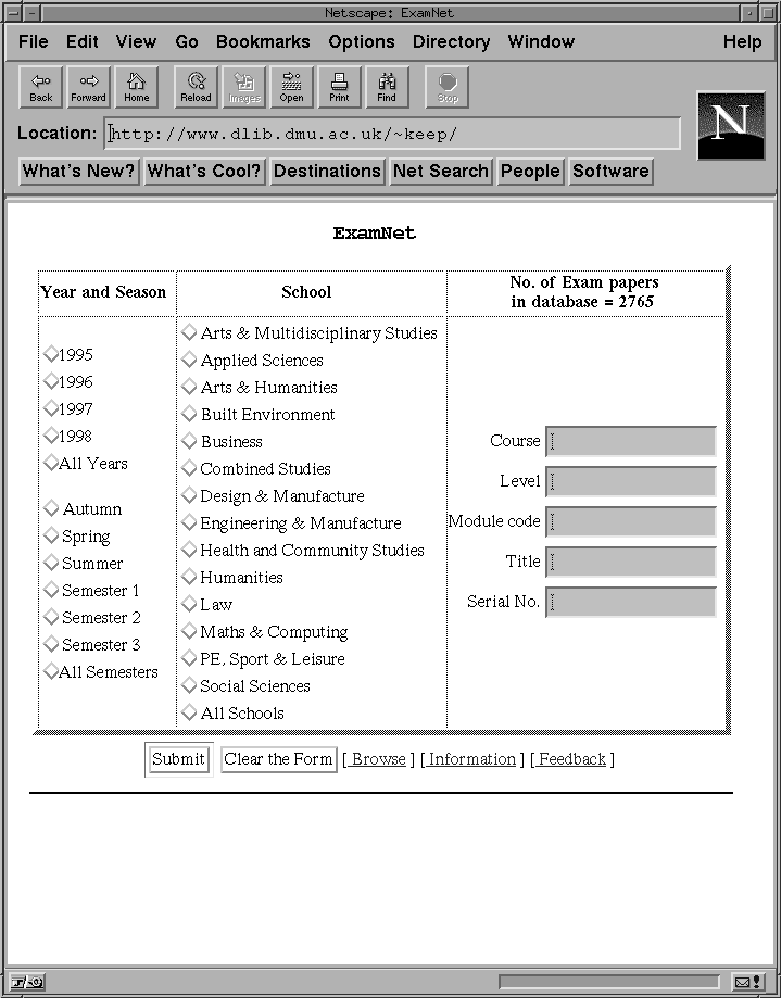
A set of HTML pages were written for browsing and building the ExamNet search query, The search query page requests the user to enter a query based on the fields of interest and is shown in Figure 2. The script that runs behind this interface is a Perl CGI program that uses regular expression to search over the copy of the exam database file.
Access to the entire system is restricted via the HTTPD Authentication HTACCESS mechanism [1] to ensure that only DMU and trusted users can view the information.
The papers may be found by searches over the following fields that formed the parametric data :
![]()
For example: if one wanted to search for all exams within a certain year or semester then one would click on that year and semester and then on "Submit". If the user knows the actual Exam Serial number then this can be used instead.
The usage of the system
The project was launched in April 1998 and logs of access has been kept to discover the popularity of certain exams and the frequency of usage. The graph below shows the usage of the system over a 12 month period.
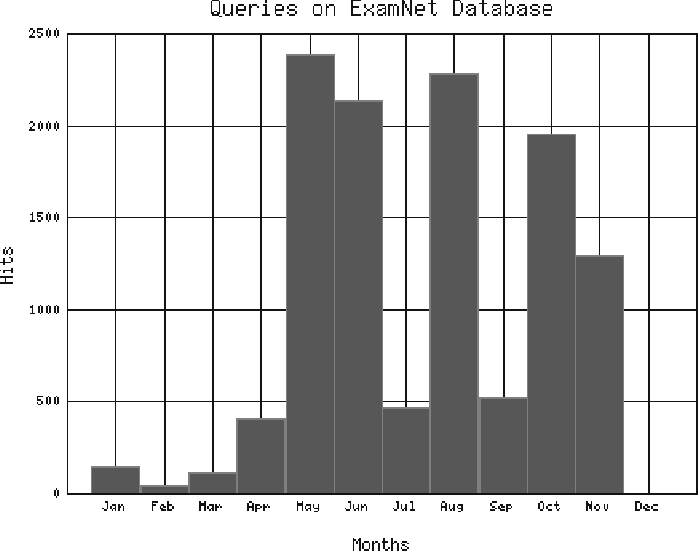
In order to help users take full advantage of the system a help guide was written, published and placed in strategic areas all around the library. A copy of this is included with this article.
Typical comments received from users relate to the following areas:
- Speed
- The DMU library provides access to the Internet via 200 networked PCs. When the network is fully loaded users may experience unacceptable delays. There is little the ExamNet system can do about this.
- Search query
- The search interface has been designed to mirror the database entry system. Although there may be a short learning curve to negotiate, the majority of users find the system acceptable due to its compactness and flexibility.
- Bad data
- Due to the nature of the data scanned and the different scanning staff involved in the project, numerous problems were discovered with mathematical formulae and images, and with exams that had been scanned incorrectly. This was anticipated and errors discovered normally initiate a rescan where appropriate.
- Access
- Although copyright has not been an issue regarding exam papers, access to the system has been restricted to DMU users. User authentification is established by computer .dmu.ac.uk domain addresses. If computers are not registered or access is required from machines at users’ homes then this is currently not possible.
Conclusions
Although the main aim of the project was to automate provision and facilitate access of exam papers to the DMU community it was also motivated by the need to reduce staff involvement in managing a past examination paper service. A cost benefit analysis has shown that the time spent by staff administering ExamNet compared to the old paper version is significantly reduced. However, having stated this, new skills are required by library staff in scanning, OCRing, database and Internet technologies. The time taken for staff to acquire these skills will offset the cost benefit, although it is estimated that as the system becomes more widely adopted and understood by librarians the cost benefit will become more noticeable.
From the users’ perspective the ExamNet offers an opportunity to browse and search for subject matter that is relevant to the individual. Whilst there is a learning curve to negotiate the practical benefits over the old paper based system are soon apparent. There is no longer the need to queue at library points, the system is available from anywhere in the campus and at any time of the day. Printing selected exam papers can be done locally or within the university library. Searching is fast and flexible over the entire database or individual exams. Feedback from users have shown that the system is popular and is becoming more popular as news of its existence becomes known.
The system at present relies upon a single server processing many client requests. If an access fault occurs to the server then the service will become unavailable and this is obviously an unacceptable situation. Although there is little to be done if the fault lies in the network, a degree of resilience can be ensured by mirroring the main server data. Investigations are currently underway at DMU to study the implications of such a fall-back system strategy.
The methods adopted to solve the problems faced in providing an on-line past exam papers system may appear to be numerous and technically challenging. This is because the problems of providing such a system are non-trivial. There is no easy way of moving from one medium to another. In an ideal world exam papers might well be produced entirely in an electronic format that would make the conversion to the target PDF format relatively simple and straight forward. In the real world this would involve establishing constraints on faculties and departments to monitor quality assurance, restrict software usage and ensure staff are computer literate. This is neither practical nor desirable in a decentralised establishment such as a modern university.
We have demonstrated that with careful thought, planning and training a system can be designed and implemented that is beneficial to the library and to users.
References and Contributions
The work on the ExamNet system at DMU was undertaken by numerous people from with the library, the digital library group and others. The working system could not have been achieved if it had not been for the contribution from multiple disciplines of librarianship, information systems and computer science. The following people are responsible for making ExamNet work :
- Owen Williams
- - our systems administrator and UNIX guru
- Adrian Welsh
- - our Adobe Capture and PC expert
- Louise Taylor
- - our librarian who did all the documentation and got us to see the user perspective
- Kirsten Black
- - our library systems manager who did the organising
- John Knight
- - our hard working placement student from computer science who did the API programming for the Adobe Capture system
- Nick Hunter
- - our database expert
- Pete Robinson
- - for inspiration
- Numerous librarians
- - who learnt the scanning system and spent any number of hours scanning and recording their efforts for the database.
[1] HTTP Access: http://hoohoo.ncsa.uiuc.edu/docs-1.5/tutorials/user.html
Author Details
David James HoughtonProject Manager, ExamNet
The Library
The Gateway Leicester LE1 9BH
Tel: +44 (0) 116 250 6349
Email: djh@dmu.ac.uk
URL: http://www.dlib.dmu.ac.uk/