Windows NT Explorer
In this new column, I hope to bring users' attention to the value of employing Windows NT server technology within their institution. While Windows NT has its fair share of problems, there is no denying that the quality of server-side software available for this platform has improved enormously in the last 12 months.
Kicking off, this article examines the use of Microsoft's Site Server 3.0 [1] to provide a sophisticated web based search solution for your institution.
Crawling Websites
One problem that many institutions have is the proliferation of web servers. These are almost certainly to be based on a range of Unix, Linux and Windows systems. Consequently, this makes it difficult to employ many search systems that use the file system to catalogue documents. Furthermore, some servers will almost certainly contain restricted access areas, obsolete pages, development pages, and other items that should not really be catalogued. Site Server avoids these problems by employing a sophisticated web robot (the Gatherer) to catalogue documents. The Gatherer will therefore enter a website via the 'front door', and will only be able to index documents that a normal user would be able to gain access to (unless you specifically want it to index restricted documents).
Although the Gatherer can be used to crawl websites, file systems, databases and Exchange Server Public Folders, crawling websites is its most common role. The Gatherer is controlled from either the Microsoft Management Console (MMC - see Figure 1), or via a Java compatible browser using the Web-based Administration interface (WebAdmin - see Figure 2).
There are plenty of options to control the behaviour of the Gatherer. To prevent website and/or network overloads, there is the ability to alter the frequency that documents are requested from the remote servers. The Gatherer also obeys the proposed Robots Exclusion standard [2], as well as the 'robots' <META> tag embedded within individual pages. If you aren't able to use robots.txt files on certain sites, there is also the ability to prevent the Gatherer indexing specific paths, but I have found this to be fairly time consuming to configure.
During the crawling process, the admin interface can be used to check on the progress of the crawl (Figure 1). There is also an extensive logging facility, which assists with troubleshooting. You can of course schedule the Gatherer to update Catalogues at specific times (this uses the standard Windows NT Task Scheduler).
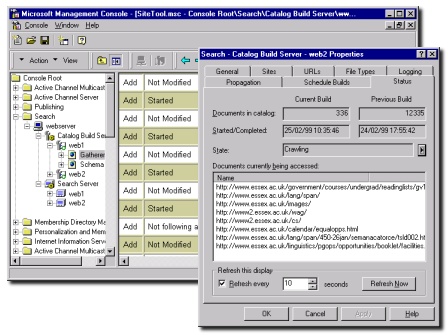
Figure 1: The Microsoft Management Console is used to manage the Search facility
Catalogue Generation and Propagation
Once the Gatherer has trawled a site, it will generate a new Catalogue for that site. Site Server supports a maximum of 32 Catalogues per machine (although a single Catalogue can store details about more than one site). The size of these Catalogues obviously depends on a number of factors, but as a example, the Catalogue for our main web server (2,500 documents) takes up approximately 22 Mb of disk space. The Catalogue contains information about a large number of document properties (e.g. title, description, size, MIME type), most of which are user-configurable via the Catalogue's Schema (see Figure 2).
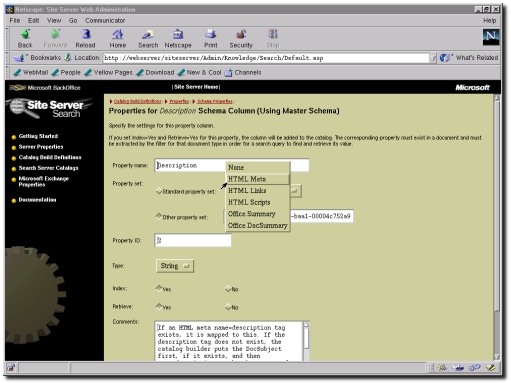
Figure 2: Configuring a Catalogue Schema using the WebAdmin interface
If you have more than one machine running Site Server, it is also possible to propagate Catalogues between machines. This saves having to repeatedly crawl the same documents.
Customising the Search Interface
One problem with many 'off the shelf' web search facilities is that they do not always look like they actually belong to your site. At Essex that was certainly the problem with our original search facility (which used Excite for Web Servers [3]). By contrast, the search pages for Site Server can be completely customised to reflect your site's corporate image. I created the Essex search facility [4] in Microsoft FrontPage 98 (see Figure 3), although if I was writing the page again I would consider using something like Visual InterDev [5] or EasyASP [6]. An advantage of FrontPage 98 is that it allows easy switching between the WYSIWYG and HTML source view, and as long as you are aware of its idiosyncrasies, it won't mess up your scripting.
Figure 3: FrontPage 98 was used to create the search page
There are plenty of sample Active Server Pages (ASP) supplied with Site Server, and the documentation (in HTML format) is excellent. Since the examples are all in Visual Basic (Scripting Edition), this is the recommended language for creating server-side ASP search facilities. One useful facility is the fact that you are able to search the Catalogues through the MMC or WebAdmin interface, so you don't have to create your own search facility before you can determine that the Gatherer has worked as intended.
The documentation and samples make it fairly straightforward to create a huge variety of search pages. There is also some excellent information available from third party websites, such as the Site Server section of 15seconds [7] and SiteServer.com [8]. Creating pages that show a certain number of records per page isn't too difficult. I also worked out how display a small icon to indicate the MIME type of the document (e.g. HTML, PDF, DOC etc.), and also to give a graphical display of how closely the document matched the search term.
For users wishing to create sophisticated search pages, Site Server allows you to narrow down results by document properties. For example, the Essex search facility allows searching of the title, description, or the entire document. There are also options to specify which server is searched, and also to find documents modified within a certain time period. Site Server also supports some other advanced features that I haven't yet incorporated into our search page, such as the facility to do plain English searches, restrict search results to those documents containing a specific <META> tag, and extensive foreign language support.
One plus point is the ability of Site Server to index a wide range of documents. Out of the box it has the ability to catalogue web pages, text files and Microsoft Office documents. Additional filters (called IFilters) can be added if required. Adobe have a filter for Acrobat PDF documents available for free download from its website [9]. There is also a filter available for Corel WordPerfect documents [10]. If these types of documents are to be indexed, the Gatherer has to be specifically instructed to catalogue the appropriate file types (identified by file extension).
Other Issues
So far, the Site Server search facility has caused few problems. Site Server can be quite resource intensive, and for large institutions wanting to catalogue many resources, it may be worthwhile to purchase a dedicated machine. It is also unfortunate that search pages written to use Microsoft's Index Server without Site Server (such as the University of Essex Computing Service website search page [11]) need extensive code modification if they are to be used with SiteServer.
Summary and Conclusions
One thing that came out of the Institutional Web Management workshop held in September 1998 [12] was the need for institutions to establish effective site searching tools. I have found Site Server to fulfil this requirement perfectly - it is fast, relatively easy to use, reliable, and access statistics show it is consistently in the top ten most frequently requested pages on our servers.
References
- Microsoft Site Server, website
<URL: http://www.eu.microsoft.com/siteserver/> - Proposed Robots Exclusion standard, web page
<URL: http://info.webcrawler.com/mak/projects/robots/norobots-rfc.html> - Excite for Web Servers, website
<URL: http://www.excite.com/navigate/> - University of Essex (search facility), web page
<URL: http://www2.essex.ac.uk/search/> - Microsoft Visual InterDev, website
<URL: http://msdn.microsoft.com/vinterdev/> - EasyASP, website
<URL: http://www.optweb.net/ebanker/easyasp/> - Site Server section of 15seconds, website
<URL: http://www.15seconds.com/focus/Site%20Server.htm> - SiteServer.com, website
<URL: http://www.siteserver.com/> - IFilter for Adobe Acrobat documents, web page
<URL: http://www.adobe.com/prodindex/acrobat/ifilter.html> - Corel IFilter for WordPerfect documents, web page
<URL: http://www.corel.com/support/ftpsite/pub/wordperfect/wpwin/8/cwps8.htm#wpifilter> - University of Essex Computing Service (search facility), web page
<URL: http://www2.essex.ac.uk/cs/search/> - Report on the "Institutional Web Management" Workshop, Brian Kelly, Ariadne issue 17
<URL: http://www.ariadne.ac.uk/issue17/web-focus/>
Author Details
 Brett Burridge
Brett Burridge
University of Essex
Computing Service
Wivenhoe Park
Colchester
Essex, CO4 3SQ
Email: brettb@essex.ac.uk
Brett Burridge is a Systems Programmer in the Computing Service at the University of Essex.