Web Focus: Report on the WWW 8 Conference
The Eighth World Wide Web Conference (WWW8) was on a smaller scale than in the past few years. The numbers of delegates seemed to be down, and there was no accompanying exhibition. The conference appeared to be refocussing on the web research community, with delegates from commercial companies more likely to be software developers than marketing types. This refocussing also seemed to be reflected in the conference papers, which, as a number of people commented, seemed to be of a higher quality this year.
Unlike last year (in which RDF was the main conference highlight, as reported in Ariadne 15 [1]) and the previous year (with XML being the important new technology, which was also reported in Ariadne 9 [2], this year the general consensus seemed to be that no major new developments had been announced. This is, perhaps, a consequence of the increasing complexity of the web. The intricate inter-dependencies of new protocols and data formats, the resources needed to move along the development of the protocols and interoperable demonstrators, and various political barriers are inevitably slowing down developments. Many web developers are no doubt pleased with this news!
Tim Berners-Lee still has a clear vision of the future of the web, which he described in his keynote talk on Challenges of the Second Decade [3]. In his talk he restated his original aims for the web (initially made 10 years ago [4]), and noted that a number of the aims, in particular universal writing has still not been achieved. He acknowledged that this is a difficult problem to solve (although W3C work with their Amaya browser/editor and the Jigsaw server software seemed to working satisfactorily for W3C staff). However he acknowledged the need for stability and to "slow down, get it right". His final part of the talk outlined his vision for the "Semantic Web" (which he had previously described in his keynote talk entitled "Evolvability" at WWW7 [5]). RDF is still regarded as the key to deployment of the semantic web.
In his keynote talk, Tim gave a personal view on the dangers of software patents to the development of the web. His comments referred to three patent claims related to core web technologies:
- Intermind's patent (no. 5862325) [6] covers rights related to metadata control mechanisms which, according to Intermind, cover implementations of P3P.
- Sun's patent (no. 5659729) [7] which covers technologies relevant to XLink.
- Microsoft's patent (no. 5860073) [8] which covers technologies relevant to style sheets.
- Hill ECatalog's patent (no. 5528490) [9] which covers technologies for online presentation of catalog materials.
The patent issue, together with related topics such as IPR and open source software, was brought up in many informal discussions at the conference. I was told, for example, that although a "cold war" exists between the major computer companies (such as IBM, Sun and Microsoft) they are reluctant to use the ultimate weapon (company lawyers!) as this will be costly for all (especially since these companies own so many patents that they are likely to be unknowingly infringing patents. But the large computer companies are worried when patents are held by smaller companies or individuals, since they may not play by the "club rules". Richard Stallman, who was awarded the Yuri Rubinsky award at the end of the conference (ironically a cash donation from Microsoft!), alerted delegates to the proposals to legalise software patents in Europe and encouraged them to view the FreePatents web site [10] - which also priovides details on the Intermind and Microsoft patent claims.
Papers
A total of 48 technical papers were selected by the Programme Committee. A brief summary of several of them is given below. The papers themselves are available online [11]. In addition the Printed Proceeding are published by Elsevier [12].
There were three papers from the UK Higher Education community given at the conference (two of which are mentioned in this report). Charlotte Jenkins et al gave a warmly-received paper on Automatic RDF Generation For Resource Discovery [13]. Automated tools for the creation of metadata are much-needed in order to implement enhanced seach engines. As Nicky Ferguson commented in his trip report: Exactly the right paper at the right time [14].
The second paper from the UK was given by Rob Procter of Edinburgh University. His paper on Improving Web Usability with the Link Lens addressed the human factors of a URL. A link lens (a browser aid) provides information (metadata) associated with a hyperlink.
There were two other papers which described use of browser aids - an area relevant to project work at UKOLN and ILRT, University of Bristol. Visual Preview for Link Traversal on the World Wide Web [15] described the use of a proxy service which enables a visual preview of a website to be displayed, before the user "goes" to the website. A live version of prototype is available (as described at [16]). The third example was described in the paper on Surfing The Web Backwards. In this example a Java-based browser aid was used to display "backlinks" - links to the current page, based on the link information which can be obtained from HotBot.
Yoelle Maarek's paper on Adding Support for Dynamic and Focused Search with Fetuccino was her third paper presented at the last three WWW conferences. Last year's paper described Capuccino - a Java-based visualiser for sitemaps. This idea has been developed into a Java-based tool for the visualisation of search results, as shown below.
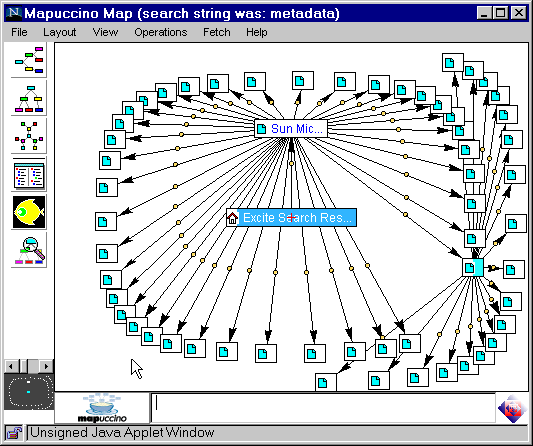
Figure 1: Fetuccino
A prototype of this service is freely available [17].
This application can be used to post-process results for a number of search engines. In the light of comments made by search engine vendors at the Panel Session (see below) I asked Yoelle if she was concerned that her "parasitical" (as some would class it) application would not be appreciated by the search engine vendors. She responded that the application emulates an end-user session and only processed relatively small numbers of the results set so this shouldn't be a problem. (It was also pointed out that IBM have their own search engine - Clever - which could be used by Fetuccino). After the session finished I discussed this issue with someone from Compaq/AltaVista. His view was that the search engine vendors know when their results are being post-processed, and if this is being used in a production service, financial arrangements would have to be agreed.
Panel Sessions
As well as the paper sessions, there were also several panel sessions. At these sessions, several experts in a subject area would typically give brief presentations, which would be followed by general discussions and questions from the floor. The panel sessions included Finding Anything in the Billion-page Web: Are Algorithms the Key? [18], Mobile Computing and Accessibility [19], Web-Based Everything: are HTTP, DAV and XML Enough? [20], and Agents vs Direct Manipulation: What's Best to Disentangle the Web? [21]. I attended the first of these sessions.
The panel session on Finding Anything in the Billion-page Web: Are Algorithms the Key? consisted of panelists from Yahoo! (Udi Manber), Excite (Brian Pinkerton) and two from Compaq, the owners of AltaVista (Andrei Broder and Monika Henzinger). There seemed to be some agreement amongst the panelists that hardware was not a significant barrier to the development of better searching service. More sophisticated algorithms were felt to be of importance. Perhaps understandably, the panelists refused to divulge their views on these algorithms in any detail, although citation analysis (such as Google [22], which featured in the report on last year's conference [2]) was mentioned. Udi Manber also mentioned the need for search engines to understand the word not. He illustrated this point with the example of a parent searching for web resources "suitable for children". Unfortunately this currently retrieves documents which contain the words not suitable for children!
Other suggestions for areas in which we can expect developments include personalisation and user profiling, and specialist (rather than general purpose) search engines. With a growth of specialist search engines, we can expect to see 2-layer searches (e.g. find search engines which deal with medical resources, and then submit a search to the relevant search engines). This model will be very familiar to the UK's subject based information gateways and the Phase 3 eLib projects.
Brian Pinkerton (Excite) also made a number of comments which will be of interest to the metadata and subject gateway communities. He felt there was a need to construct "web collections" and to make use of "impartial" metadata - which can include citations (as Google does, as mentioned above) as well as third party reviews. Third party reviews of web resources is a good description of subject gateways, such as SOSIG, OMNI and EEVL. It was pleasing to hear a major search engine vendor making these comments.
Poster Session
In addition to the technical papers, conference delegates also received a copy of the Poster Proceedings. The Poster Proceedings consisted of short papers (about 2 pages). These papers were peer-reviewed. The short papers were accompanied by posters, and the programme provided a 2 hour slot for participants to view the posters and talk to the authors. The posters were available for casual viewing for the duration of the conference.
A list of the Posters and the authors is available on the WWW8 website [23]. A brief summary of several of the posters is given below.
Roddy MacLeod of the EEVL service and myself co-authored a poster on Subject-Based Information Gateways in the UK [24]. The aim of this paper was to ensure that the work of the subject gateways was documented for the web research community, and to identify areas of interest to the subject gateways for future work. The short paper was accompanied by several colour posters, illustrated below.
As noted In Nicky Ferguson's conference report [14], the poster provided a valuable focal point for delegates with an interest in this area, and several useful contacts were made.
Southampton University's Multimedia Research Group were again present at the conference. Their paper on A Distributed Link Service Using Query Routing outlined use of the whois++ and CIP protocols to integrate their Distributed Link Service with other link services.
The National Caching Service, and institutional proxy managers may be interested in the paper on WebTransformer: An infrastructure for Web content transformation. This paper describes a proxy service for transforming web content - such as converting images or removing adverts. Their WebTransformer software has recently been ported to Squid. This topic occasionally surfaces on the wwwcache-users Mailbase list, but as members of this list will be aware, there are significant legal and ethical considerations which need to be addressed.
The paper on i Proxy: An Agent-Based Middleware also described proxy software which could be used for transformation purposes. This software is freely available from AT&T [25].
The paper on CyberGenre and Web Site Design used the random.yahoo.com website to return 96 random web sites, which were analysed. Several categories (referred to as CyberGenres) were identified: 'Home Page,' 'Brochure,' 'Resource,' 'Catalogue,' 'Search Engine' and 'Game'. Although this does not appear to be an adequate categorisation, their approach may be of interest to the metadata community.
The paper on ConfMan: Integrated WWW and DBS Support for Conference Organization will be of interest to anyone wishing to use a web-based tool for managing academic conferences. The paper includes a review of conference management software [26]. The software described in the paper is also freely available [27].
An example of a US-based subject gateway was described in Efficient Web Spidering with Reinforcement Learning, which describes aspects of the Cora project (illustrated below) [28].
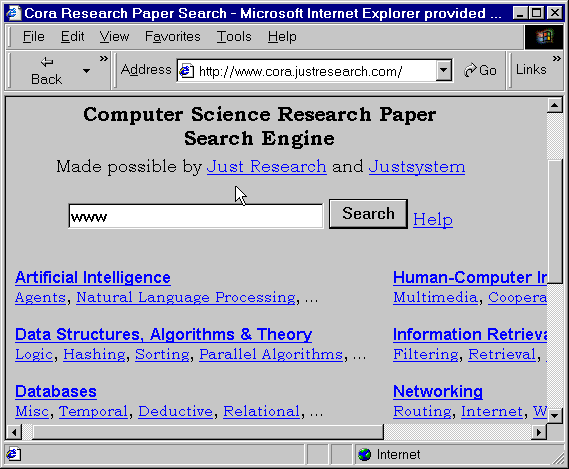
Figure 2: CORA
The paper on Scientific Literature Indexing on the Web also described a prototype service which can be used to access scientific literature, known as ResearchIndex [29]. This project aims to produce algorithms and techniques that can be implemented in any digital library, and not just to produce another digital library of scientific literature.
A prototype web tracking service is described in the paper on Website News: A Website Tracking and Visualisation Service. A number of websites are visited by a spider on a regular basis, and changes to the website are recorded. This enables changes to a website over specified periods to be displayed, as illustrated below (changes to the Microsoft website between 1 April and 19 May 1999) [30].

Figure 3: "Website News
The paper on jCentral: Search the Web For Java described jCentral [31], which is the largest repository of Java resources on the Internet. This service has been available since summer 1997 (and was featured in Developer's Day at WWW7). A new service called xCentral [32]. was announced in April 1998. xCentral provides a similar service to jCentral, allowing structured information on XML resources to be found. As the press release states, xCentral is part of an emerging trend toward "specialized" search engines. [33]. As noted elsewhere, the specialist search engine was a recurrent theme at the conference.
W3C Track
W3C staff members gave several presentations during the conference on developments to web standards. This talks covered the Web Accessibility Initiative (WAI), Television and the Web, an XML Update, HTML, Building Trust on the Web (P3P), Signed XML Documents, Query Languages, Style Sheets, SMIL (Multimedia for Everyone) and Web Characterisation. The slides are all available on W3C's web site [34].
The most impressive demonstration of an emerging new W3C format was given by Chris Lilley in his talk on SVG (Scalable Vector Graphics, although the term Sexy Vector Graphics has also been used!) [35]. As the name implies SVG uses a vector rather than bitmapped graphical format. This has several benefits including smaller file sizes and the ability to resize graphics. Although such features are familiar to users of CAD packages, the ability to make use of such technologies on the web using open data formats is very exciting.
As always with new web technologies, there is always the question of deployment. A W3C Note on Composite Capability/Preference Profiles (CC/PP): A user side framework for content negotiation [36] may provide a solution. The CC/PP protocol proposes an exchange mechanism between a web server and browser, by which the browser gives a description of its capabilities, such as sound and image capabilities, hardware attributes such as screen size, colours and CPU, support for cookies, scripting, etc. Although it is still early days for this proposal, the protocol (which is based on HTTP's Extension Framework is worth tracking.
WWW 9
Next year's conference, WWW 9, will be held in Amsterdam on 15-19 May, 2000. Further information will be made available (probably around August) at http://www9.org/ As the conference is being held so close to the UK it would be good to see plenty of contributions from the UK HE community. For those who are interested the deadline for submission of papers is 22 November 1999.
Feedback
The author welcomes feedback on this article. Please send email to b.kelly@ukoln.ac.uk. Any WWW8 delegates who have written their own trip reports is encouraged to inform the author of this article so that a record of WWW8 trip reports can be kept.
References
- Web Focus Corner: WWW7: The Seventh International World Wide Web Conference, Ariadne, Issue 15
<http://www.ariadne.ac.uk/issue15/web-focus/> - Web Focus Corner: Report on the WWW 6 Conference, Ariadne, Issue 15
<http://www.ariadne.ac.uk/issue9/web-focus/> - Challenges of the Second Decade, Tim Berners-Lee, W3C
<http://www.w3.org/Talks/1999/05/www8-tbl/Overview.html> - The Original Proposal of the WWW, Tim Berners-Lee, W3C
<http://www.w3.org/History/1989/proposal.html> - Evolvability, Tim Berners-Lee, W3C
<http://www.w3.org/Talks/1998/0415-Evolvability/overview.htm> - United States Patent 5,862,325: Computer-based communication system and method using metadata defining a control structure , US Patent and Trademark Office
<http://164.195.100.11/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/srchnum.htm&r=1&f=G&l=50&s1='5862325'.WKU.&OS=PN/5862325&RS=PN/5862325>
Also available at <http://www.patents.ibm.com/details?pn=US05862325__&language=en> - United States Patent 5,659,729:Method and system for implementing hypertext scroll attributes, US Patent and Trademark Office
<http://164.195.100.11/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/srchnum.htm&r=1&f=G&l=50&s1='5659729'.WKU.&OS=PN/5659729&RS=PN/5659729>
Also available at <http://www.patents.ibm.com/details?pn=US05659729__&language=en> - United States Patent 5,860,073: Style sheets for publishing system , US Patent and Trademark Office
<http://164.195.100.11/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/srchnum.htm&r=1&f=G&l=50&s1='5860073'.WKU.&OS=PN/5860073&RS=PN/5860073>
Also available at <http://www.patents.ibm.com/details?pn=US05860073__&language=en> - United States Patent 5,528,490: Electronic catalog system and method , US Patent and Trademark Office
<http://164.195.100.11/netacgi/nph-Parser?Sect1=PTO1&Sect2=HITOFF&d=PALL&p=1&u=/netahtml/srchnum.htm&r=1&f=G&l=50&s1='5528490'.WKU.&OS=PN/5528490&RS=PN/5528490>
Also available at <http://www.patents.ibm.com/details?pn=US05528490__&language=en> - Free Patents - Protecting Innovation & Competition in the IT Industry, FreePatents.org
<http://www.freepatents.org/> - WWW8 Conference Refereed Papers, WWW8
<http://www8.org/fullpaper.html> - Proceedings of the Eighth International WWW Conference, Journal of Computer Networks and ISDN Systems, Vol. 31, May, 1999, Elsevier
- Automatic RDF Metadata Generation for Resource Discovery, Charlotte Jenkins
<http://www.scit.wlv.ac.uk/~ex1253/rdf_paper/> - Report from WWW8 conference - Toronto, Nicky Ferguson, ILRT, University of Bristol
<http://www.ilrt.bris.ac.uk/~ecnf/www8.html> - Visual Preview for Link Traversal on the WWW (Abstract), Theodorich Kopetzky and Max Mühlhäuser
<http://www.tk.uni-linz.ac.at/~theo/publications/VisualLinkPreview_abstract.html> - Visual Preview for Link Traversal on the WWW, Theodorich Kopetzky and Max Mühlhäuser
<http://www.tk.uni-linz.ac.at/~theo/demonstrations/scientific/VPLT_Demo.html> - Fetuccino, IBM
<http://www.ibm.com/java/fetuccino/> - P1 Panel - Finding Anything in the Billion-Page Web: Are Algorithms the Answer?, WWW8
<http://www8.org/wed-details.html#P1> - P2 Panel - Mobile Computing and Accessibility, WWW8
<http://www8.org/wed-details.html#P2> - P3 Panel - Web-based Everything: Are HTTP, DAV and XML Enough?, WWW8
<http://www8.org/wed-details.html#P3> - P5 Panel - Agents vs Direct Manipulation: What's Best to Disentangle the Web?, WWW8
<http://www8.org/thurs-details.html#P5> - Google home page, Google
<http://www.google.com/> - Conference Posters, WWW8
<http://www8.org/posters-final.html> - Subject-Based Information Gateways in the UK, B. Kelly and R. MacLeod
<http://www.ukoln.ac.uk/web-focus/papers/www8/> - i Proxy: An Agent-Based Middleware, AT&T
<http://www.research.att.com/sw/tools/iproxy/> - Summary of Conference Management Software, Rick Snodgrass, University of Arizona
<http://www.cs.arizona.edu/people/rts/summary.html> - ConfMan, UniK
<http://confman.unik.no/> - Cora, JustResearch.com
<http://www.cora.justresearch.com/> - ResearchIndex, NEC Research Institute
<http://www.scienceindex.com/> - Website News, AT&T Laboratories
<http://www.research.att.com/~chen/web-demo/> - jCentral, IBM
<http://www.ibm.com/developer/java/> - xCentral, IBM
<http://www.ibm.com/developer/xml/> - IBM launches first XML search engine, IBM
<http://www2.software.ibm.com/developer/news.nsf/xml-current-bydate/5EFDFE286FA13522852567600054DBB2?OpenDocument> - W3C Talks, W3C
<http://www.w3.org/Talks/#1999> - SVG, W3C
<http://www.w3.org/Graphics/SVG/> - Composite Capability/Preference Profiles (CC/PP): A user side framework for content negotiation, W3C Note,
<http://www.w3.org/TR/NOTE-CCPP/>
Author Details
 Brian Kelly
Brian Kelly
UK Web Focus
UKOLN
University of Bath
Bath
BA2 7AY
Email: b.kelly@ukoln.ac.uk
Brian Kelly is UK Web Focus. He works for UKOLN, which is based at the University of Bath