Web Cache: Clashing with Caching?
Why are UK universities using Web caches?
Whenever a student or academic tries to connect to a Web page, there is a significant chance that another person has already viewed the same Web page in the not too distant past. If a Web page is based on a US machine, it can be slow and expensive to load directly from the US, so it is worth saving a copy of the Web page on a UK-based ‘Web cache’ (which is sometimes called a ‘proxy cache’, to distinguish it from the cache on the user’s hard drive). Then, the next person wishing to use the same page may access the cached copy more quickly and easily than they could access the original. George Neisser, of the UK JANET Web Caching Service, estimates that between 25% and 45% of the pages requested via the national cache have previously been requested and are therefore cached.[1]
Web caches are used by UK universities for the following reasons:
- To reduce unnecessary duplication of network traffic (particularly between JANET and the US) and therefore to save money.
- To minimise the time taken to download Web pages from remote sites so that use of the Web is more productive
- Because many IT support staff both within universities and outside them agree that Web caching is ‘vital to the future scaling of the Web’ (as Jon Knight puts it [2]).
- Because universities are following a national strategy, as outlined in JISC Circular 3⁄98 ‘Usage-related Charges for the JANET Network’[3], which encourages use of the National Cache.
Clearly, there are major advantages to using Web caches. Many organisations now recognise this and Web caching is now widely used by universities and other organisations. However, many academic librarians are very aware that there can be a clash between Web caching and providing access to the electronic information resources to which their institutions subscribe. The problems are outlined below and some suggested solutions are given.
It is important that we all get this right, otherwise it reflects badly on caching and on electronic information resources in general. Users who run into difficulties accessing a particular service or e-journal may avoid trying to access that resource in future or they may try to avoid using the cache in future. They will not necessarily ask for help.
Caching and IP address authenticated subscription services
Most academic librarians in the UK first encountered problems with using Web caches when the Institute of Physics Publishing (IOPP) launched its electronic journal service. The IOPP e-journal service was originally accessed via user name and password, but IP address based authentication began to be used in 1995, to save users having to remember passwords.
At that time, many Web browsers in UK HE were set up to use the HENSA Web cache in all cases where the hostname of the service did not include ac.uk The hostname of the IOPP e-journal service was www.iop.org, so calls to this service went via the cache. This meant that the user’s IP address appeared to be the IP address of the HENSA cache and not the IP address of the user’s machine, and therefore the user was not allowed to access the service.
Back then, many librarians simply advised users of the IOPP e-journals service to configure their browser to the ‘no proxies’ setting, so that the national cache would not be used and the IP address based authentication would work. These users then lost the advantages of Web caching. It would have been possible for people to configure more advanced browsers so that the cache was not used when the user was trying to connect to IOPP, but was used at other times. Unfortunately, however, the method of doing this varied from browser to browser and it would have required a higher level of technical knowledge than many users and librarians possessed at that time.
Since then, many other Web-based electronic subscription services have become available and many of them have made use of IP address based authentication so that users could avoid having to remember passwords and/or to establish that users were accessing the services from a campus. Daniel Feenberg, of the National Bureau of Economic Research, sums up the view of many service providers when he says, ‘The advantage for us – minimal clerical effort – is also an advantage for our customers’.[4]
At the same time, the use of Web caching has also grown. The old HENSA cache has now been replaced by the national UK JANET Web Caching Service (JWCS), which is based at Manchester Computing Centre, Loughborough, and the University of London Computing Centre. There has also been an increase in the use of smaller Web caches based at individual HE institutions.
And, as with the IOPP e-journals service, there is an inherent conflict between Web caching and IP address based authentication. For example, if a user tries to connect to a Web-based service via the national cache, then that Web-based service will ‘see’ the IP address of the cache rather than the IP address of the user’s computer. The Web-based service may then deny the user access on the grounds that the user does not appear to be based on the campus of a subscribing institution.
Should we abandon IP address based authentication?
Some of the ‘cachemasters’ (staff who manage Web caches) on the wwwcache-users mailing list[5] have suggested that IP address based authentication should be abandoned, and that we should revert to having usernames and passwords for each service. Apart from the conflict with caching, they say, IP addresses are too easy to forge and it is foolish to restrict services to campus users when more and more staff and students need to connect from home.
However, librarians and service providers would not be keen on having a separate password for each service, because:
- there is a huge administrative load caused by having multiple passwords to issue;
- users cannot easily remember or keep track of multiple passwords; and
- passwords can be circulated between authorised users and unauthorised ones.
It is also worth noting that some institutions subscribe to over 100 electronic journal services and other services which use IP address authentication. It would be very difficult to re-negotiate acceptable alternative methods of authentication with each of the service providers concerned, especially given that many of those service providers specified that they wanted access to be restricted to users based on campus. We could, however, work to ensure that future authentication arrangements are made with an awareness of caching.
Is ATHENS the solution?
We could try to encourage more publishers and service providers to use the ATHENS authentication system, which does not rely on IP address based authentication if users have personal usernames and passwords.
This would have the following advantages:
- The ATHENS system is now established, and is beginning to have ‘brand recognition’ amongst university staff and students.
- Users will only have to remember their ATHENS username and password, rather than usernames and passwords for each service.
- This will enable those users who have personal ATHENS usernames to access services from home.
However, ATHENS passwords would not be a complete solution for the following reasons:
- ATHENS is a proprietary standard, which publishers have to pay to use, and this is a deterrent to wider use.
- Some publishers and service providers may be uncomfortable about users accessing their services from home.
- More users will require personal usernames and passwords - and some institutions have so far tried to avoid individual user names and passwords, because of the administration involved.
- There is some concern from IT support staff that ‘single sign on systems’, where the same password is used for a large number of different services, pose a big security risk.
Incidentally, self-registration for ATHENS personal usernames and passwords is IP address authenticated, but this should not be a problem if all .ac.uk calls are sent direct by the browser or the site cache stage.
Sending requests direct without going via a Web cache
We can no longer encourage users to ‘switch off’ the Web cache every time they wish to access an IP address authenticated service because this would require users to understand their browsers, and to know which services use IP address authentication. There is also the risk that users will not bother to reconfigure their browsers to switch the use of the Web cache back on – with consequent charging implications for the institution. Also, some institutions force all calls though the site cache, so users cannot ‘switch off’ use of the cache.
However, we can configure our site caches and our Web browsers to send requests to IP address authenticated services directly to the appropriate Web sites without going via a cache. The following notes describe what we do at Birmingham.[6] (This is also illustrated in figure 1.)
Suppose we have a Web browser configured to use the Site Cache, and a Site Cache configured to use the National Cache, whenever the Web browser is asked to retrieve a Web object, the following decisions will be made by the Web browser and the Site Cache:
The Web browser decides whether or not to retrieve the Web object directly from source or via a cache. In particular, the following directives are used;
- Web objects located at Web sites using Hostname or IP Address authentication schemes are retrieved directly from source. This is because the required Web object may be restricted to callers using a particular Hostname or IP Address at a subscribing institution.
- Web objects at Web sites whose Hostnames end with ac.uk (i.e. Higher education Web Sites in the UK Domain) are retrieved directly from source.
- All other requests are sent to the Site Cache
- If the Site Cache is down, all Web objects are retrieved via one of the National Cache machines.
- If all of the National Cache machines are down, all Web objects are retrieved directly from source.
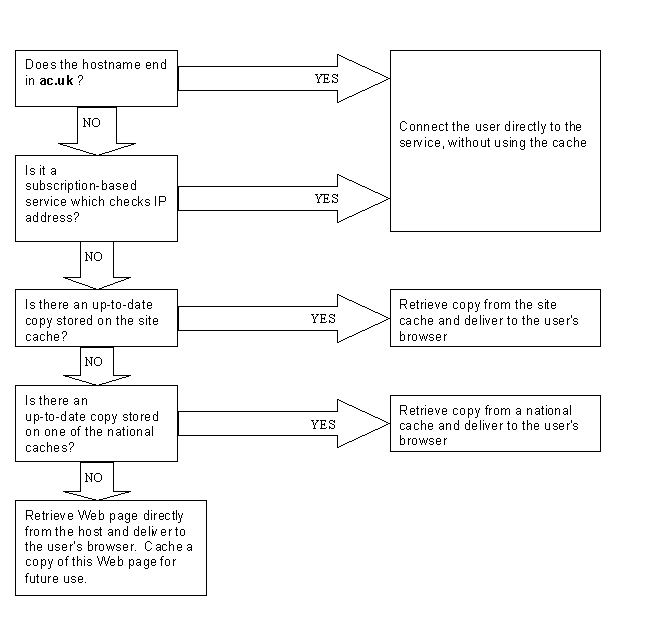
Figure 1: Summary of the decisions taken to decide whether to use a cache or send the request direct
The above directives can be encoded in two places:
- a Proxy Auto Configuration File (or PAC file); a JavaScript program which supplies rules to the browser on how to retrieve a Web object.
- an Access Control List (ACL) file in the Site Cache itself
These PAC and ACL files effectively contain a list of hostnames of services which check IP addresses (such as www.janet.idealibrary.com and abstracts2.rapra.net) for which requests for Web pages should be sent direct. Using ACL files is the most effective method, because this avoids potential problems with browser incompatibility or port blocking.
This approach works reasonably well most of the time, and many universities have worked out how to do something similar. However, it is not without its problems. For one thing, this cannot be done centrally by the UK JANET Web Caching Service. The request has to be sent direct before it reaches a national (UK JANET Web Caching Service) cache. This means that universities or departments within universities must use a properly configured site cache rather than going straight to the UK JANET Web Caching Service.
Setting up an ACL file in the site cache and/or a PAC file in the Web browser can be done by the local cachemaster. In most cases this is a trivial task for the local technical support people – the slow and difficult bit may be ascertaining which sites need to be accessed direct. Currently, each individual university has to maintain a list of the services to which this applies, and keep up-to-date with the new services and changes. And each site is coming up against problems with some services whose hostnames ‘jump about’ (see the section on ‘Mirror Sites’, below, for more details) or which have other peculiarities.
To a certain extent, it is reasonable to expect Universities to maintain their own lists of hostnames for which requests should be sent direct, because each Universities subscribes to a slightly different portfolio of services. However, we ensure that we all share the information and solutions we have found, rather than reinventing wheels, particularly when a major service is launched or changes hostname or develops a quirk.
This exchange of information has begun to happen already. People have sent e-mails on this topic to the wwwcache-users, lis-link, lis-jibs-users and arl-ejournal electronic mailing lists, for example. Also, Martin Hamilton has now created a ‘What should I do about IP address based Authentication?’ section in the JWCS Frequently Asked Questions Web pages. (This includes a useful example ACL list containing many of the hostnames of subscription services used by UK universities, which people are welcome to suggest additions to.) We should build on this. Not surprisingly, there can sometimes be a problem communicating about caching across the ‘librarian-techie divide’, but this is not insurmountable.
What is the cost of sending requests direct?
Some Universities may be concerned at the prospect of sending requests direct, especially to US Web sites, because one aim of Web caching is to save money. However, cachemasters estimate that IP address authenticated services only constitute a small proportion of total Web use.[5]
Incidentally, requests for dynamically generated pages, of which there are an increasing number, are usually sent direct. By default the ‘Squid’ software, which governs most university caches, fetches pages containing ‘cgi-bin’ or ‘?’ direct (and doesn’t cache them) because such pages are frequently generated ‘on the fly’ or related to forms etc. This means that most electronic journals and other subscriptions services are not very cacheable anyway.
Mirror sites
Another way to avoid conflict between IP address based authentication and caching is to create UK-based mirror sites for subscription services which have their main server outside the UK. If the mirror site has a hostname ending in ac.uk, most university site caches will send the request direct.
One example of this is the CatchWord mirror. This is what CatchWord have to say about this (at http://figaro.catchword.com/janft.htm)
Web users originating from within the UK academic community (‘JANET’ users) are increasingly employing the JANET web proxy cache in order to reduce their internet traffic costs. Site-wide subscriptions to CatchWord material are best set up using registrations that employ IP address recognition: this avoids the need for users to memorise and enter username/password combinations. A web request that reaches CatchWord via the JANET proxy server will have the wrong IP address and will therefore be incorrectly recognised.
CatchWord therefore runs a server within the JANET network, kindly hosted by Birmingham University. The address of the server is http://pinkerton.bham.ac.uk/. All UK academic users should use this server, and UK librarians setting up CatchWord links on their OPAC pages should point to this server. Not only will page access be more rapid (since no intervening cache will be employed) but, being within the JANET network, no international internet traffic charges will be incurred.
If mirror services are successful, they must be complete and up-to-date in every respect. There have been some problems, for example, with the Highwire and IDEAL mirror sites which are not complete replicas of their partner sites. When some of the search features on these mirror sites are used, the journal articles retrieved are sometimes delivered from the parent site instead of the mirror site. The hostname of the parent site is different from the hostname of the mirror site, so both the parent site hostname must be added to the PAC and/or ACL files.
Changes of hostname
When JournalsOnline became ingentaJournals the hostname became www.ingenta.com.
This change of hostname was very unpopular. As well as having to update links on our Web pages, librarians also learned that it was necessary to ask our cachemasters to add this new hostname to our local PAC/ACL files (especially in this case, because the new hostname did not end in ac.uk).
When hostnames change site caches also can be configured to redirect calls from the old address to new one, which could potentially save users a lot of frustration. Obviously, this works best for those sites which force users to use the site cache.
Again, it is crucial that there is good communication between service providers, librarians and cachemasters.
Meeting the needs of off-campus students
Demand from students wishing to access electronic subscription services from home is increasing all the time. This is partly due to the increase in students who are studying part-time or at a distance but conventional students are also increasingly likely to have home PCs connected to the Internet.
Some services use IP based authentication for on-campus users but will accept usernames & passwords as an alternative method of authentication for off-campus users. Other services use ATHENS authentication and students with personal ATHENS usernames and passwords can access those services from home.
Warwick and some other institutions are also using the site cache itself to enhance access to services for off-campus users. These users can access the site cache via any Internet Service Provider they like, by entering a username and password into a pop-up box. Once they have their browser at home set up to use the site cache, they can then connect to any of the IP address authenticated services that they can access on campus. The IP address authenticated service ‘sees’ the IP address of the site cache. At Warwick, there is a special ACL file in the Squid program which makes this work. This approach requires further negotiation with publishers to check that they are happy to allow this kind of off-campus access to their services, and that the authentication is secure enough to be acceptable.
JANET National Dial-Up Service
Some members of the UK HE community are dialup JANET users using the ‘JANET national dialup service’ (JNDS), which was outsourced to an Internet Service Provider called U-Net. JNDS users get a dynamically allocated IP address which changes with every session. This causes problems with all the services which use IP address based authentication. The only way around this is offer users an alternative way to connect to these services, perhaps using a similar approach to that used at Warwick (as described in the previous section).
The ‘Via’ header
As an alternative to IP address based authentication, we could encourage publishers to use header information to ascertain the origin of the call. Calls which go via a site cache will have details about the cache in the ‘Via’ field of the header information.
It looks like this …
Via: 1.0 gadget.lut.ac.uk:3128 (Squid/2.2.STABLE3+martin)
or this… (when multiple caches are involved)
Via: 1.0 gadget.lut.ac.uk:3128 (Squid/2.2.STABLE3+martin), 1.0 panic.wwwcache.ja.net:8080 (Squid/2.1.PATCH2)
The publisher can ascertain where the request is coming from by looking at the first cache in the Via: list.
Daniel Feenberg of the National Bureau of Economic Research and Martin Hamilton, of the UK JANET Web Caching Service, have suggested that this could be investigated further.[7]
Pros:
- Many publishers would find this relatively simple to implement
- The ‘Via’ header is a standard feature of the HTTP protocol (unlike the X-Forwarded-For: header, which some publishers are using for IP address based authentication)
Cons:
- Header information is not completely reliable, because it can be forged very easily (but this also applies to IP address)
- Institutions who do not have their own site cache cannot use this approach.
- This idea has not been properly tested.
Using a local site cache to IP address authenticate users
Michael Sparks, from Manchester Computing Centre, has suggested that IP address authentication could be done by an ACL file in a local site cache rather than by the service provider [8]. This would mean that requests would not have to be sent direct to the service provider. An ACL file on the site cache could be used to ensure that only users with a certain range of IP addresses could access a particular service, and that all other users would be directed to the service provider’s ‘access denied’ page instead. This would, of course, have to be done with the agreement of the service provider.
Load balancing and cookies
When ProQuest users at the University of Warwick reported that they could no longer use the service, the problem was traced to ‘load balancing’ system used there. ‘Load balancing’ is a way of sharing the load between multiple site cache machines. Warwick staff and students are forced to use a site cache, but, because the use of local caching is so high at Warwick the site cache consists of several machines, each with a different IP address. Each time a user tries to retrieve a Web page, the call is sent to whichever site cache machine is the least busy at that moment. The ProQuest service tracks the behaviour of users by sending cookies back and forth with each transaction, this process was being confused by the fact that several different machines with different IP addresses were involved. This particular problem was solved by restricting all calls to ProQuest to a designated cache.
Both the use of cache balancing by universities and the use of cookies by service providers are likely to increase, so we will need to watch out for similar problems which may occur elsewhere in future.
Conclusion
The implications of Web caching for the users of Web-based subscription services are complex. But the advantages of caching are such that is worth trying to solve the problems it can cause for access to subscription services. Librarians need to keep themselves informed of developments with national strategy and local strategies concerning both caching and authentication, and to make sure that these strategies develop in such a way as to reduce the clash rather than increase it. There is obviously a need to keep service providers informed too. Finally, strong communication between librarians and cachemasters is vital if we are to ensure that access to subscription services is maintained.
Thanks to
Alison McNab, Jon Knight and Martin Hamilton at Loughborough University
Roy Pearce and Chris Bayliss at the University of Birmingham
Chris Tilbury and Hywel Williams at the University of Warwick
Michael Sparks at Manchester Computing Centre
This article is based on a paper originally written for the JIBS User Group.
References
- George Neisser, Caching In: The National JANET Web Caching Service (JWCS). Ariadne, No. 19, March 1999.
http://www.ariadne.ac.uk/issue19/cache/ - Jon Knight and Martin Hamilton, Wire: Interview via email, Jon Knight and Martin Hamilton in session. Ariadne, No. 9, May 1997.
http://www.ariadne.ac.uk/issue9/wire/intro.html - JISC Advisory Committee on Networking, JISC Circular 3⁄98 Usage-related Charges for the JANET Network London: Joint Information Systems Committee, March 1998.
http://www.jisc.ac.uk/pub98/c3_98.html - Daniel Feenberg, Transparent Caching and IP Address Access Lists
http://papers.nber.org/cache.html - The wwwcache-users mailbase list, archived at
http://www.mailbase.ac.uklists/wwwcache-users/archive.html
(the February 1999 thread about ‘ACLs for routing direct to problem sites’ is of particular interest) - Roy Pearce, University of Birmingham Site Web Cache Project Web pages
http://www.cache.bham.ac.uk/ - Daniel Feenberg (26 Feb 1999), Re: Authentication and Site Licenses and the Janet Cache arl-ejournal mailing list, message archived at
http://www.cni.org/Hforums/arl-ejournal/1999/0055.html - Michael Sparks (michael.sparks@mcc.ac.uk) (25 June 1999) Re: Caching Paper. E-mail to Martin Hamilton (martin@net.lut.ac.uk).
Author Details
Ruth Jenkins
Engineering Liaison Librarian / BUILDER Project Co-ordinator
Information Services
University of Birmingham
Edgbaston
Birmingham, B15 2TT
Email: r.jenkins@bham.ac.uk
Article Title: “Clashing with Caching?”
Author: Ruth Jenkins
Publication Date: 20-Sep-1999
Publication: Ariadne Issue 21
Originating URL: http://www.ariadne.ac.uk/issue21/subject-gateways/