WebWatch: UK University Search Engines
In the previous issue of Ariadne an analysis of 404 error messages provided on UK University web sites was carried out [1]. In this issue an analysis of indexing software used to provide searches on UK University web sites is given.
Although the WebWatch project [2] has finished, UKOLN will continue to carry out occasional surveys across UK HE web sites and publish reports in Ariadne. This will enable trends to be observed and documented. We hope the reports will be of interest to managers of institutional web sites.
Survey
An analysis of search engines used by University and Colleges web sites as given in the HESA list [3] was carried out during the period 16 July - 24 August 1999. Information was obtained for a total of 160 web sites.
The most popular indexing software was ht://Dig. This was used by no fewer than 25 sites (15.6%). This was followed by Excite used by 19 sites (11.9%), a Microsoft indexing tool was used by 12 sites (7.5%), Harvest was used by 8 sites (5.0%) Ultraseek by 7 sites (4.4%), SWISH/SWISH-E by 5 sites (3.1%), Webinator by 4 sites (2.5%) Netscape Compass and wwwwais were both used by 3 sites (1.9% each). FreeFind was used at 2 sites (1.3% each). Glimpse, Muscat, Maestro, AltaVista (product), AltaVista (public service), WebFind and WebStar were used by single sites (0.6% each). Six sites used an indexing tool which was either developed in-house or the name was not known (3.8%). No fewer than 59 sites (36.9%) did not appear to provide a search service or the service was not easily accessible from the main entry point. Details for one site (0.6%) could not be obtained due to the server or search facility being unavailable at the time of the survey.
A summary of these findings is given in Figure 2. The full details are available in a separate report [4].
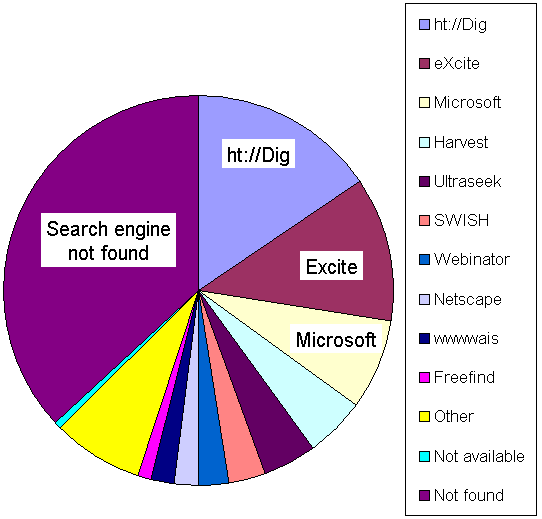
Figure 1 - Usage of Indexing Software
About The Search Engines
A brief summary of the indexing software mentioned in this article is given below. Please note that some of the details have been taken from Web Developer.Com Guide to Search Engines [5]. This book was published in January 1998. Some of the details of the indexing engines may have changed since the book was published.
- ht://Dig [6]
- ht://Dig was originally developed at San Diego State University. It is now maintained by the ht://Dig Group. The software is freely available under the GNU General Public Licence. ht:Dig uses a spider to index ("dig") resources, although it can also index resources by trawling the local filestore. It can be used to index multiple web servers. The latest version is 3.1.2.
- Excite [7]
- Excite, also known as Excite For Web Servers (EWS), was developed by Excite, one of the global searching services. Excite is available for free. Excite trawls across a file structure, rather than using a spider. This means that the benefits of HTTP access are lost. For example all files will be indexed, even if they are not linked in to the web site. Also Excite indexes only HTML and ASCII files. The EWS web site provides a security warning regarding EWS v1.1. The information was released in January 1998. This seems to indicate that the software is not being actively developed.
- Ultraseek [8]
- The Ultraseek Server indexing software has been developed by Infoseek. Although a free trial version is available, it is a licensed product.
- Microsoft
- Microsoft produce several tools for indexing web sites. FrontPage 98 provide a "webbot" which can be used to provide a simple indexing capability to a web site [9]. The IIS server provides a more sophisticated indexing tool [10]. However the SiteServer software probably provides Microsoft's most sophisticated mainstream indexing tool [11].
- Webinator [12]
- The Webinator indexing software has been developed by Thunderstone. This software is available for free.
- Harvest [13]
- The Harvest software was originally developed as part of a research project in the US. It is now being maintained by a research group at the University of Edinburgh. The Harvest software continues to be available free-of-charge.
- Glimpse [14]
- The Glimpse software was developed at the University of Arizona. The GlimpseHTTP software has now been replaced by WebGlimpse. This software is available for free.
- SWISH-E [15]
- SWISH-E (SWISH-Enhanced) is a fast, powerful, flexible, and easy to use system for indexing collections of Web pages or other text files. Key features include the ability to limit searches to certain HTML tags (META, TITLE, comments, etc.). The SWISH-E software is free.
- Maestro [16]
- Maestro has been developed for the OS/2 platform. This software is available for free.
- Muscat [17]
- Muscat claims to have advanced linguistic inference technologies.
- Isearch [18]
- CNIDR Isite is an integrated Internet publishing software package including a text indexer, a search engine and Z39.50 communication tools to access databases. Isite includes the Isearch component.
Try Them
Interfaces to examples of each of the indexing packages is given below. They are listed in order of popularity. Feel free to try them. A default search term of web is given. Move the cursor to the field and press the Enter key or click on the Go button to initiate a search.
| Name | Institution | Link to Location | Search | |
| ht://Dig | Bath | Site Search | ||
| Ultraseek | Cambridge | Local & Internet Search | ||
| eXcite | Birmingham | eXcite Web Page Search | ||
| Microsoft (SiteServer) | Essex | Search the University of Essex Web | ||
| Microsoft (Index Server) | Manchester Business School | Search Manchester Business School | ||
| Microsoft (FrontPage-bot) | Paisley | Welcome Pages Text Search | ||
| Webinator | Newcastle | Search | ||
| Netscape (Web Publisher) | Bangor | Search the University Web Site | ||
| Netscape (Compass) | UCL | Search UCL Web Servers | ||
| SWISH-E | KCL | KCL: Search | ||
| Harvest | De Montford | DMU: Search | ||
| Glimpse | Leeds | Search the University of Leeds central pages | ||
| Maestro | Dundee | SOMIS | ||
| Muscat | Surrey | Search the University of Surrey Web Site | ||
| Freefind | Northampton College | Web Site Search Engine |
It is left as an exercise for the reader to compare the different services.
Which To Choose?
If you have tried the various searching services shown above you should have a feel for the various interfaces provided by the different products. Did any of the products have a particular impressive interface?
As well as the interface provided to the user, other issues to consider when choosing an indexing package include:
- Costs. Is the software available for free or do you have to pay for it? Are the costs justified in order to provide extra functionality?
- Number of resources to be indexed. Will the software index the resources you currently have on your web site? Will the software index resources as thr web site grows?
- Open Source vs. Shrinkwrapped. Is the source code available? Do you want to have access to the source code?
- Formats to be indexed. What formats can be indexed (e.g. MS Word, PDF files, etc.)?
- Mainstream solution. Should a mainstream solution be adopted, or would you be happy to use a unusual solution if it provided the necessary functionality?
- Functionality. What functionality is provided by the software?
An alternative to installing an indexing package on your local system is to make use of a third party's index of your site. A number of companies will offer to do this. For example, Thunderstone [19], Netcreations [20], Freefind [21], Searchbutton [22] and Atomz [23], all provide a free search engine service. As shown in the table above, Northampton College make use of the Freefind service to provide an index of their web site.
A second alternative is to embed access to a global search engine within your web site, and limit the search so that only resources held on your web site are retrieved.
Although this type of search service is very easy to implement (and the public AltaVista service is used for the Derby web site) there are a number of disadvantages to this approach e.g. you have little control over the resources which are indexed, users are sent to a remote site with its own interface (and usually contains adverts), etc.
Searching Across University Web Sites
This article has reviewed the search engines used on UK university web sites. However as an awareness of the capabilities of the current generation of search engines grows, institutions are likely to consider additional uses of the packages. As well as indexing one's own web site, it is possible to provide links to indexes of remote web sites, index remote web sites, and search across several sites. A number of examples of these types of applications is given below, followed by a discussion of several issues which should be considered.
Links to Indexes Of Remote Web Sites
A increasing number of web sites provide embedded search boxes which enable users to submit search terms to remote web sites. This article contains several examples. Another example can be seen in Figure 2 which illustrates OMNI's collection of search boxes for medical-related services [26].
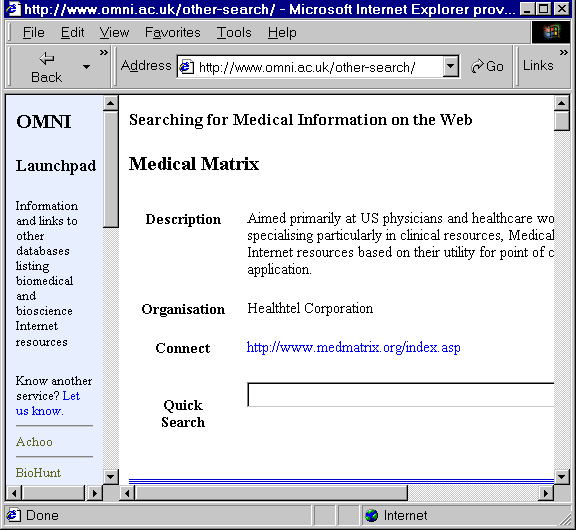
Figure 2 - The OMNI Search Interface
Searching Across Multiple University Web Sites
The OMNI interface shown above provides a single page containing multiple search boxes for searching a range of services. However each search query has to be submitted individually. It would be nice to be able to submit a single query and search multiple services.
The Universities for the North East web site provides a search interface which enables searches of several web sites to be submitted [27]. The interface is illustrated in Figure 3.
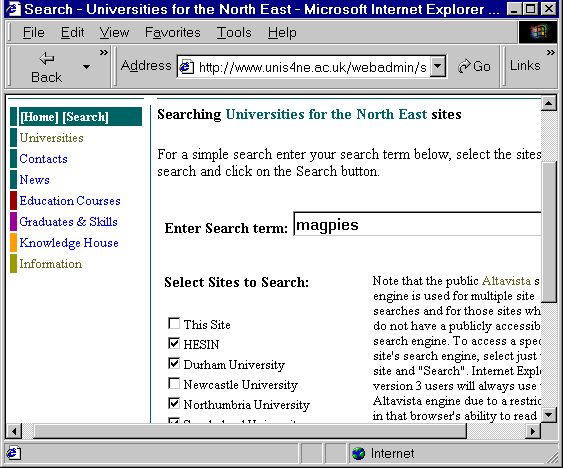
Figure 3 - The Unis4ne Cross-Searching Interface
This interface makes use of the public AltaVista service. It provides a front-end to AltaVista's advanced searching interface. As it searches AltaVista's centralised index it should not really be classed as cross-searching although from the end-user's perspective, this is what it seems to provide.
Indexing Remote Web Sites
The UCISA TLIG (Teaching Learning and Information Group) hosts a document archive [28] which provides links to computing documentation provided by computing service departments. The documents have been indexed using ht://Dig to provide a searchable archive, as illustrated in Figure 4.
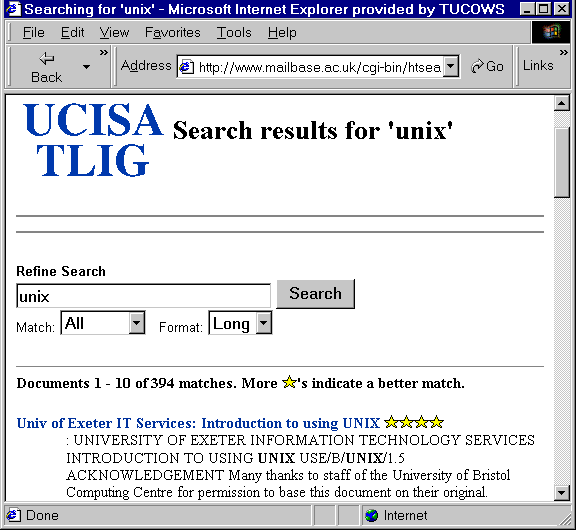
Figure 4 - The UCISA TLIG Document Archive
This is an illustration of how an index across remote sites can provide a useful service to a specialised community.
Issues
Before providing pages with embedded search boxes for a range of services or downloading the latest version of an indexing tool and setting up indexes of local services and selected remote services (or trying to index the entire web!) there are a number of issues to consider.
The following issues relate to embedded search boxes.
- Copyright Issues
- Although the large search engine vendors encourage use of embedded search boxes, and organisations such as OMNI use them, it could be argued that this should not be done unless permission has been granted. Organisations could argue that they provide value-added services on their web site and expect users to follow links to their search page. A counter-argument is that the form is used to simply create a URL which contains the input parameters which is sent to the server, and one should not be able to copyright a URL.
- Change Control
- If an organisation changes its search engine interface, it may cause remote interfaces to break.
- Framing
- If the search results are displayed in a frame, an organisation could attempt to pass off the service as belonging to them.
Note that there are technical solutions to prohibiting or managing such interfaces. Examination of the HTTP header fields for the Referer (sic) field should indicate if the search was initiated remotely. If necessary, searches initiated from remote search boxes could be prohibited, redirected to another page or the output results could be tailored accordingly.
The following issues relate to indexing remote services.
- Performance Issues
- Indexing remote web sites will require you to provide extra disk space and processing power locally. It will also add to the load and network bandwidth demands on the remote service.
- Maintenance
- Will your index become out-of-date?
- Duplication of Effort
- Will you simply duplicate other search services?
Within the commercial world, there is much interest in indexing of remote services. This can be used, for example, to index competitor's web sites. Within the Higher Educational community, there is more likely to be interest in indexing local community web sites (e.g. institutions within the regional MAN) or related subject areas (e.g. particle physics web sites, or, as described above, computing service document archives).
Conclusions
This article does not provide a Which-style recommendation on the best indexing software. Rather it describes the packages which are currently deployed within the community. The main recommendation is that institutions should, from time to time, review the indexing packages which are available and deployed within the community in order to avoid being left behind. A search engine provides a very valuable tool for visitors to a web site. It is arguably more important that a modern, sophisticated search engine is provided on a web site than the web site look-and-feel is updated to provide a more modern-looking interface.
In the longer term we are likely to see interest in the functionality of search engines focus not only on the interface provided, file formats indexed, etc. but also on how reusable the results returned are and the ability to search across non-web resources. Why should we expect results only to be used directly to link to a resource? What if the results are to be stored in a desktop bibliographical management package, or automatically included in a standard way in a word-prcessed report? And wouldn't it be nice to be able to search across the institution's OPAC, as well as the web site?
The use of remote indexing services, such as the public AltaVista or the FreeFind service may have a role to play. Such services may provide a simple solution for institutions which have limited technical resources for installing indexing software locally. They may also have a role to play in providing a search service if the local facility is unavailable (e.g. due to a server upgrade).
The author welcomes comments from managers of web services, and invites them to send comments to the website-info-mgt Mailbase list [29].
Further Information
If you are interested in further information on indexing software see Builder.com's article on Web Servers: Add search to your site [30], Searchtools.com's article on Web Site Search Tools [31], or SearchEngineWatch.com's Search Engine Software For Your Web Site [32].
References
- WebWatch: 404, Ariadne issue 20
http://www.ariadne.ac.uk/issue20/404/ - WebWatch, UKOLN
http://www.ukoln.ac.uk/web-focus/webwatch/ - Higher Education Universities and Colleges, HESA
http://www.hesa.ac.uk/links/He_inst.htm - Survey Of UK HE Institutional Search Engines - Summer 1999, UKOLN
http://www.ariadne.ac.uk/issue21/webwatch/survey.html - Web Developer.Com Guide to Search Engines, ISBN 0-471-24638-7
Further details available at the Amazon web site - ht://Dig, ht://Dig
http://www.htdig.org/ - EWS Home, Excite
http://www.excite.com/navigate/ - Ultraseek, Infoseek
http://software.infoseek.com/products/ultraseek/ultratop.htm - Web Workshop - FrontPage 98: Adding a Search Form to your Web Site, Microsoft
http://msdn.microsoft.com/workshop/languages/fp/dev/search.asp - Index Server FAQ, Microsoft
http://www.microsoft.com/NTServer/fileprint/exec/feature/Indexfaq.asp - SiteServer: Implementing Search in the Enterprise, Microsoft
http://www.microsoft.com/SiteServer/site/30/gen/searchwp.htm - Webinator, Thunderstone
http://www.thunderstone.com/webinator/ - Harvest, University of Edinburgh
http://www.tardis.ed.ac.uk/harvest/ - WebGlimpse, University of Arizona
http://donkey.cs.arizona.edu/webglimpse/ - SWISHE-Enhanced, Digital Library SunSITE
http://sunsite.berkeley.edu/SWISH-E/ - Search Maestro, Dundee
http://somis.ais.dundee.ac.uk/general/maestroabout.htm - Muscrat empower, Muscat
http://www.muscat.com/corporate/empower.html - CNIDR Isite, CNIDR
http://vinca.cnidr.org/software/Isite/Isite.html - Free Search Engine Service, Thunderstone
http://index.thunderstone.com/texis/indexsite/ - Pinpoint, Netcreations
http://pinpoint.netcreations.com/ - FreeFind Search Engine, FreeFind
http://www.freefind.com/ - FreeFind Search Engine, Searchbutton
http://www.searchbutton.com/ - Atomz.com Search Engine, Atomz
http://www.atomz.com/ - iSeek Search Applications, Infoseek
http://infoseek.go.com/Webkit?pg-webkit.html - Help | Tools, HotBot
http://www.hotbot.com/help/tools - Searching For Medical Information on the Web, OMNI
http://www.omni.ac.uk/other-search/ - Search - Universities for the North East, Unis4ne
http://www.unis4ne.ac.uk/webadmin/search.htm - UCISA TLIG Document Sharing Archive, UCISA
http://www.ucisa.ac.uk/TLIG/docs/docshare.htm - website-info-mgt, Mailbase
http://www.mailbase.ac.uk/lists/website-info-mgt/ - Web Servers: Add search to your site, Builder.com
http://www.builder.com/Servers/AddSearch/ - Web Site Search Tools - Information, Guides and News, Searchtools.com
http://www.searchtools.com/ - Search Engine Software For Your Web Site, SearchEngineWatch.com
http://searchenginewatch.internet.com/resources/software.html
Author Details
 Brian Kelly
Brian Kelly
UK Web Focus
UKOLN
University of Bath
Bath
BA2 7AY
Email: b.kelly@ukoln.ac.uk
Brian Kelly is UK Web Focus. He works for UKOLN, which is based at the University of Bath