I Say What I Mean, but Do I Mean What I Say?
"Interoperability is easy. It’s a piece of cake. Simply digitise (or create in digital form) a load of content and stick it on a web site. To let people find it, use this cool stuff called metadata. Basically, that means describing your stuff by writing a description of it inside some <META> tags."
Erm… Wrong!!! The prevalence of this view — or views remarkably akin to it — is truly scary, even amongst the ranks of those such as readers of Ariadne, from whom we might reasonably expect better. Whilst it appears that The Battle For Metadata might almost be won, with an increasing number of people bandying the word around in a meaningful fashion, a number of closely related issues such as terminological control appear a step too far at the moment.
In this paper, I’ll take a look at some of the issues surrounding the use of controlled terminology, report on the recent MODELS 11 workshop [1] which attempted to tackle some of them, and outline some of the recommendations for future work which arose from that workshop and a similar one held by the North American National Information Standards Organization (NISO) at the end of 1999 [2].
The need for control…
Across the world, a wealth of information is being placed on the Internet and made potentially accessible to all. Previously inaccessible offerings from memory institutions [3], government, and the private sector are being offered for access, with a presumption that users will find what they want within these resources. The UK [4] is not alone in having a notion of ‘joined-up Government’, where the Citizen might conceivably expect seamless access to information of relevance to them, regardless of the particular Civil Service computer system from which the information originated. UK Higher Education’s Distributed National Electronic Resource (DNER), too, envisages a similar picture for information relevant to the Higher Education community [5], and related ideas are increasingly prevalent elsewhere in the UK and overseas.
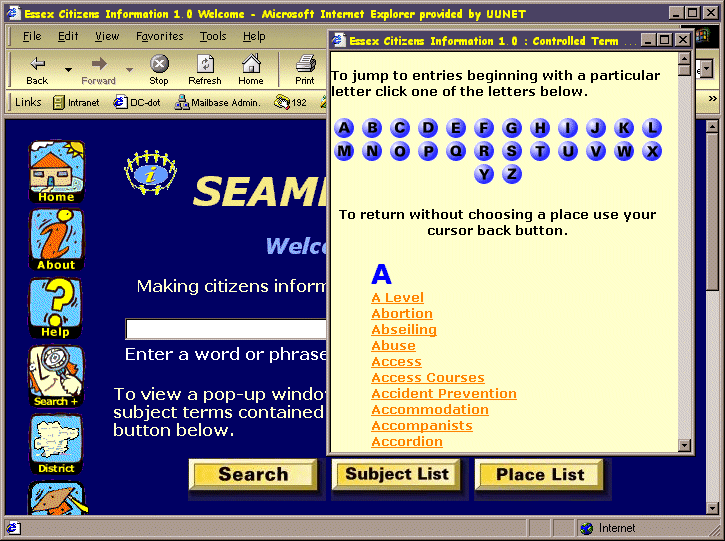
Figure 1: An example of what’s possible: the SEAMLESS Project will offer integrated access to information from a number of public sector bodies across Essex (© 1999-2000 Essex Libraries)
At the heart of these visions there necessarily lie at least two things. The first is the use of some mechanism for querying multiple resources simultaneously. Here, Z39.50 is a prime contender [6]. The second, more relevantly to this paper, is some commonality of content or description across the information resources being made available for searching.
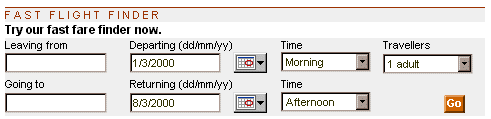
Figure 2: Expedia’s Fast Flight Finder tool (© 2000 Expedia Inc.)
Even in a simple example, such as that illustrated in Figure 2, there is a need for commonality of both content and description for this service to work. Here, the online travel service, expedia.co.uk, allows users to search multiple airlines and routes to find the most timely or cost-effective way from one place to another. For such a service to work, all of the airlines and travel agencies must presumably either agree to describe airlines, aeroplanes and destinations using the same terminology, or else use differing terminologies with closely defined correlations. Imagine the chaos if KLM, say, called New York City by its old name of New Amsterdam. If I were then to search for — and book — a flight from my local airport to Amsterdam, I might unwittingly end up on the other side of the North Atlantic, rather than the other side of the North Sea as I probably intended. A silly example, admittedly, but the opportunities for more realistic foul-ups are many and varied.
A further example, drawn from a memory institution, is that of plant and animal taxonomy. Here, the original Linnaean system of taxonomy from the eighteenth century continues to be used and extended around the world as a means of naming flora and fauna. Although there continues to be disagreement over minutiae, the system as a whole is widely recognised and adopted, and is invaluable in underpinning global biology and natural history. Figure 3 shows an example from the Integrated Taxonomic Information System [7] for a bird (the class, aves). This particular bird is a Pelecanoides urinatrix, which a quick web search discovers is commonly known as the Diving Petrel [8]. Figure 4 shows the same bird, but here the taxonomy is represented graphically, using a tool implemented by Dave Vieglais at the University of Kansas [9].

Figure 3: The Integrated Taxonomic Information System (© ITIS)
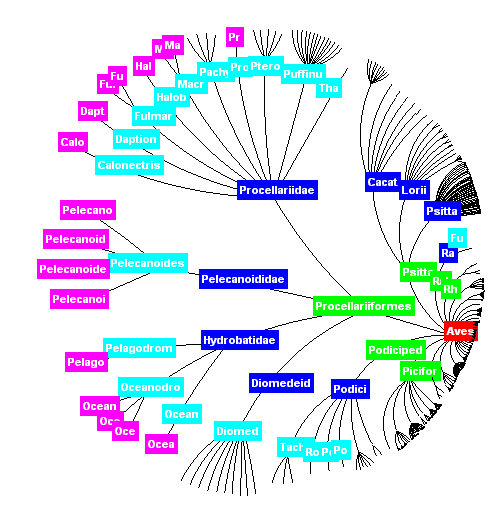
Figure 4: A graphical view of bird taxonomy (© University of Kansas)
What control gives us
To ensure common meanings across applications, and between users and applications, the normal solution is to impose a degree of control upon the terms used by both parties. At its most basic, this control will involve no more than defining a list of words, from which application and user have to select. In more complex instances, fully formed thesauri may be employed, rich with hierarchy, synonyms and relationships.
In a distributed online environment lacking any form of control over terminology, users will of course still find things. Search engines such as Alta Vista demonstrate this admirably, although the large number of hits they return (315,645 for a search on ‘thesaurus’), and the frequently irrelevant occurrences of the term for which you searched, clearly show their weaknesses. In such an uncontrolled environment, users will consistently either use the wrong terms, or use the right terms in the wrong contexts. They will also suffer from significant information overload, whilst potentially failing to discover a number of significant resources appropriate to their search.
In this same uncontrolled environment, the creators of resources face a number of problems, too. In describing their resources, they will potentially use terms inconsistently; either using a single term to mean slightly different things, or else describing very similar objects using entirely different terms. Without the adoption of hierarchically capable terminology resources, it will be extremely difficult to adequately convey hierarchical concepts. A hierarchical thesaurus, for example, might represent the countries of the United Kingdom in a hierarchy, such that anything catalogued as being in or related to England would also automatically be in or related to the United Kingdom. Hierarchies such as these are an important aspect of effective categorization, and their absence both greatly reduces effective recall and potentially increases data entry and storage requirements. Finally, failure to adopt tools such as these make it potentially impossible to effectively integrate different resources from within a single institution, or across multiple institutions. Without such underpinnings, visionary initiatives such as the DNER or Government Portals are much lessened, and potentially even worthless to many users.
Word lists, thesauri, and other tools
So, if we recognise that consistent use of terminology is beneficial to both creators and users of our resources, how can we go about creating the terminologies with which to be consistent?
The set of terminology tools might loosely be divided into three groups; controlled vocabularies, alphanumeric classification schema, and thesauri. The distinctions are not always wholly clear, however, and each of these groups has much in common with the other two.
Controlled Vocabularies
Possibly the simplest of all, a controlled vocabulary is often little more than a list of words or phrases. These terms may be offered to the cataloguer as they describe resources or, as with the SEAMLESS example in Figure 1, made available to the end user as part of the searching process. Lists such as these may be created manually, or in the case of tools presented to the end-user, generated automatically by harvesting all of the keywords in a database. In some cases, users will only be allowed to select one of these terms, whilst in others they will also be able to manually enter search terms of their own.
Alphanumeric Classification Schema
Alphanumeric schemes are well known to most people who have used a library. Whilst you might not intuitively know that a code of 060 refers to ‘General organisations and museology’, nor that 948 is the ‘History of Scandinavia’, many people do successfully navigate their libraries and locate books using this Dewey Decimal Classification scheme every day [10]
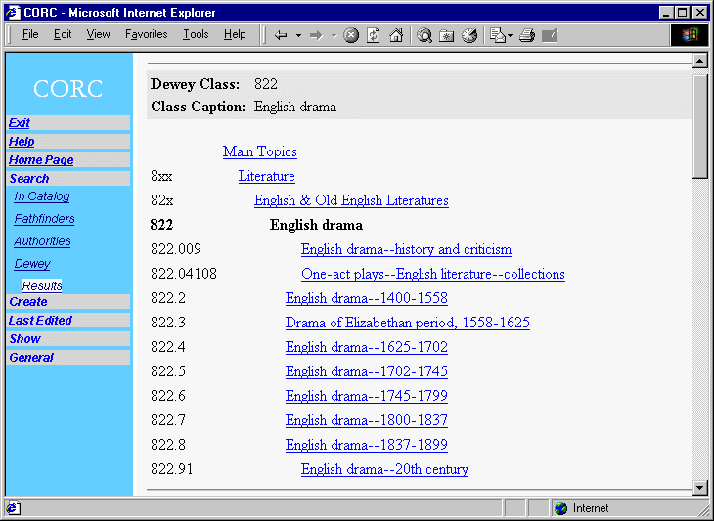
Figure 5: Browsing through one of the Dewey Decimal classes in CORC. Image taken from Diane Vizine-Goetz’ presentation to MODELS 11 workshop © 2000 OCLC
Dewey Decimal is not the only such classification scheme in use. The Universal Decimal Classification (UDC) [11] is also used in libraries, and appears similar upon casual inspection. Outside the library sector, well-known subject specific classifications of this nature include the art world’s ICONCLASS [12] and the Association for Computing Machinery’s (ACM) Computing Classification System [13]. These and other classification schemes are discussed in more detail in a deliverable from the European DESIRE project [14].
Thesauri
Mention of a thesaurus is liable to make most readers think of the humble book resting on their bookshelf, probably next to their dictionary. This book records words (synonyms) with meanings similar to that of a given word, and may also record a number of words (antonyms) with meanings opposite to that of the given word. My Collins thesaurus, for example, lists synonyms of ‘terminology’ as ‘argot, cant, jargon, language, lingo, nomenclature, patois, phraseology, terms, and vocabulary’. There are no antonyms given.
In the context under discussion here thesauri are far more, being the most complex terminological resources to be examined, with many of them including quite complex hierarchies, detailed scope notes to define each term offered, and rich inter-relationships across different branches of the whole.

Figure 6: English Heritage’s National Monuments Record has gathered a number of its thesauri together for easy online access (Image © English Heritage)
As a rule, such thesauri follow the structural guidance laid down in international standard ISO 2788 (or ISO 5964 for multilingual thesauri). It is also generally the case — as with controlled vocabularies and alphanumeric classifications — that depressingly few of these valuable resources are available online, making it difficult to build them into user interfaces.
A thesaurus structure is underpinned by three basic types of relationship; those of Equivalence, Hierarchy, and Association. Additionally, the notion of a Scope Note is fundamental to any effective deployment of thesaurus-based terminology.
Equivalence
The equivalence relationship essentially allows the thesaurus builder to offer synonyms for terms. Importantly, it also enables the designation of a ‘preferred term’ from amongst these synonyms. This preferred term is used differently by various systems, but might most usefully be considered as a display term, such that no matter which of the synonyms was entered in creating a record, it will normally be the display term that is initially shown to the user (who can, of course, search for this term or any of its synonyms and retrieve records catalogued by any of the synonymous terms).
For example, the Thesaurus of Monument Types [15] has Power Station as a preferred term for Electricity Plant and shows it, thus:
- Electricity Plant
USE POWER STATION
Hierarchy
An important capability of thesauri is their ability to reflect hierarchies, whether conceptual, spatial, or terminological. Individual entries in a thesaurus will often be linked to a broad class (denoted by the abbreviation CL), as well as to broader (BT) and narrower (NT) terms.
For example, a Bayonet is placed within a hierarchy in the mda Archaeological Objects Thesaurus [16], thus:
- BAYONET
CL Armour and Weapons
BT Edged Weapon
NT Plug Bayonet
NT Socket Bayonet
This entry may be translated as saying that a bayonet is classed as being either armour or a weapon. More specifically, it is a kind of Edged Weapon, and there are two special kinds of bayonet; the Plug and the Socket. A search for Bayonets would also find resources indexed as being Plug Bayonets or Socket Bayonets.
Association
In any sizeable thesaurus, there is likely to be a need to express relationships with terms in other branches of the overall hierarchy. Related Terms (denoted by the abbreviation RT) are used to make these hierarchy-spanning associations.
For example, a Church might be related to the curtilage and to other examples of ecclesiastical structure mentioned in the Thesaurus of Monument Types [15], thus:
- CHURCH
RT Churchyard
RT Crypt
RT Presbytery
Scope Notes
Thesaurus terms can often be terse, and extremely difficult to interpret for the non-expert. Scope Notes (denoted by the abbreviation SN) serve to clarify entries and avoid potential confusion. Importantly, especially for multilingual resources, they serve to embody a definition of the underlying concept, rather than any language-specific word.
For example, a Chitting House exists within the Thesaurus of Monument Types [15], but there are probably very few readers of Ariadne who could even begin to guess what one might be. The Scope Note serves to make things clearer:
- CHITTING HOUSE
SN A building in which potatoes can sprout and germinate
Scope Notes also serve to clarify potentially ambiguous definitions, as in this example of a Ferry:
- FERRY
SN Includes associated structures
All together, now…
This example, also drawn from the Thesaurus of Monument Types [15], demonstrates many components of the thesaurus structure:
- FERROUS METAL EXTRACTION SITE
SN Includes preliminary processing {broadens the definition a bit}
CL Industrial {is industrial in nature}
BT Metal Industry Site {is a type of Metal Industry Site}
NT Ironstone Mine {these mines are a type of Ferrous Metal Extraction Site}
NT Ironstone Pit {these mines are a type of Ferrous Metal Extraction Site}
NT Ironstone Workings {these mines are a type of Ferrous Metal Extraction Site}
RT Ironstone Workings {see also Ironstone Workings}
MODELS 11
English Heritage, mda, the British Library, and others in the UK have significant long-term expertise in the creation and deployment of terminological tools. At the same time, an increasing number of projects and services are moving significant quantities of data into an online form, and hoping for users to search within and across these newly available resources. It is widely recognised that some help is needed if the user is to have any realistic chance of discovering data across diverse systems, catalogued to different standards (where formal standards were used at all), and drawn from various curatorial traditions. It is equally recognised that many of the large-scale services which are emerging lack access to existing expertise, and in a significant number of cases attempts are being made in isolation to develop new tools when existing ones might serve better.
It was in this environment of disjointed expertise and need that UKOLN and mda planned the eleventh workshop [1] in the MODELS Programme, with funding from eLib. The intention was to outline many of the issues surrounding the construction of terminological resources, to assess the requirements of the emerging large-scale services, and to build bridges between the communities of expertise and need that currently exist within the UK.
In the end, nearly 50 people — drawn from Higher Education, the cultural heritage sector, government, libraries, and beyond — gathered at the Stakis Hotel in Bath for two days, and discussed a wide range of issues. The discussion was informed by presentations from a range of experts from the UK and beyond. As well as the scheduled presentations [17], the group received impromptu discussions of the issues from a number of participants, namely; Sandy Buchanan (talking about the experiences within SCRAN [18], and highlighting the importance of ensuring terminological consistency within individual SCRAN-funded projects, whilst outlining the difficulties of maintaining many standards across projects), Maewyn Cumming (who discussed current moves towards a set of government-spanning resources for both internal and public use [19]), Tanya Szrabjer (who discussed the significant problems of managing over one million records within the British Museum [20]), Damian Robinson (who highlighted the problems lack of control brings, with some 39 terms for the same time period within a single resource housed at the Archaeology Data Service [21]), Mary Rowlatt (who pointed to the experience within SEAMLESS [22] which showed that technically connecting resources was far easier than actually getting them to work together in any meaningful fashion), and Alan Robiette (who discussed the concept of the HE Mall [23] as a promotional showcase for the UK Higher Education sector, ideally drawing information from a host of institutional websites in a near-automatic fashion).
Workshop Outcomes
The workshop incorporated some wide-ranging discussion, resulting in a number of tasks being identified for further work. The bulk of these will be reported on the workshop website [1], with only the main points drawn out here.
-
There was widespread agreement amongst those gathered for the workshop that terminological issues were crucial to many of the developments currently underway to make complex information resources available online, and it was felt to be important that their significance be made known to a number of the influential bodies capable of directing work in this area (CITU for government, MLAC for memory institutions, and JISC for Higher Education). UKOLN was tasked to approach these bodies.
-
A number of participants pointed to the apparent lack of venue for discussion of wide-ranging terminology issues, feeling that it might be useful to have a forum suitable for carrying on many of the workshop’s discussions. It is certainly feasible to set up an electronic mailing list for such a purpose (thesaurus@mailbase.ac.uk ?), and the author seeks thoughts from Ariadne readers on the value of such a list.
-
A stated aim of the workshop from the outset was to explore the value and practicality of creating a single high-level thesaurus which might be used across a wide range of on-line resources in order to facilitate a basic level of interoperability. The University of Strathclyde and UKOLN agreed to take forward a recommendation for work in this area, and an expression of interest has subsequently been submitted to the Research Support Libraries Programme (RSLP) to extend the current SCONE project.
-
Throughout the workshop, there were repeated examples of individuals mentioning highly relevant work or initiatives (such as NKOS, the Networked Knowledge Information Systems [24]) that were unknown to the majority of attendees. It was strongly felt that some form of scoping study might usefully be funded in order to identify and synthesise a significant body of appropriate material. Such a scoping study could then be used to inform work aimed at addressing gaps in knowledge and provision.
Extending this concept, it was also felt that a single first point of contact for those beginning to address terminological issues for their online resources might be valuable. This might most usefully be placed within an existing organisation.
-
There was some discussion of automatic indexing and classification tools such as Autonomy [25]. These appear to have some potential, but it was felt that some formal evaluation work was required in order to compare these tools with the more traditional methods of manual classification.
-
It was recognised that no single thesaurus or other terminological tool will ever meet all the needs of all users. It was therefore seen to be important to hold reliable and consistent information about a range of terminological resources in order to aid those searching across data catalogued according to more than one terminology to map effectively. Such a registry would need to include information on quality, scope, degree of take up, and other aspects of a resource. It was suggested that CIDOC’s [26] Standards Group were exploring the creation of such a registry, and this should be investigated. The NISO workshop in November of 1999 [2] was also active in this area, discussing the need for a new NISO standard to provide guidance on the creation and deployment of electronic thesauri. It seems sensible to move forward alongside NISO in this area.
-
Finally, it was recognised that there was a need to study user behaviour with respect to terminology. Whilst a Local Authority, for example, might organise information by departments or directorates, the Citizen is unlikely to think in the same way. Indeed, in many cases their need will span multiple departments, and they are therefore likely to be best served by information structures which differ from the underlying organisational structures.
It was suggested that work might usefully be done to capture and study the types of vocabulary that users utilise when presented with search interfaces, remembering that the searches they undertake may not be what they consider optimal, but rather what they expect to get the best results from a system in which they potentially have little confidence. There was talk of moving towards a situation in which the system moved from being essentially a hindrance towards becoming an intelligent intermediary, akin to the human subject librarian who guides a reader towards their desired resources.
Conclusion
Terminological tools such as thesauri are an important foundation in effectively creating, curating, and re-using rich information resources in an on-line environment. In spite of this, their take-up has been slow and patchy, in part doubtless due to their perceived complexity, and to their relative lack of availability online or as part of off-the-shelf tools.
This workshop identified a great number of valuable uses for these resources, as well as a number of work items which will require attention before they can be widely deployed.
It is to be hoped that this workshop marks the beginning of a wider recognition of these resources and their value, and that terminological tools will become firmly established at the core of emerging services such as the DNER and the People’s Network.
Acknowledgements
The MODELS 11 workshop was jointly organised by UKOLN and mda, and made possible by funding from the Electronic Libraries Programme (eLib).
The meeting itself was Chaired by Gillian Grayson of English Heritage, with its smooth running ensured by Joy Fraser, UKOLN’s Events Manager. Thanks are due both to Gill and to Joy, as well as to the speakers and attendees who made it such a worthwhile event.
Thanks again to Gill — and to Matthew Stiff of mda — for reviewing a late draft of this paper. Thanks also to Neil Thomson of the Natural History Museum for pointing me towards Dave Vieglais’ Integrated Taxonomic Information System (ITIS) browse tool, and to the SEAMLESS Project team for letting me at a pre-release version of their Gateway. Any errors or omissions remain my own.
UKOLN is funded by the Library and Information Commission, the Joint Information Systems Committee of the Higher Education Funding Councils, as well as by project funding from the JISC and the European Union. UKOLN also receives support from the University of Bath where it is based.
Interoperability Focus is based at the University of Hull, and receives additional support from this institution.
References
- The MODELS 11 workshop page is at: http://www.ukoln.ac.uk/dlis/models/models11/
- The report on NISO’s Electronic Thesauri workshop is at: http://www.niso.org/thes99rprt.html
- Scientific, Industrial, and Cultural Heritage: a shared approach. A research framework for digital libraries, museums and archives explores the notion of memory institutions in the online environment. It is available from: http://www.ariadne.ac.uk/issue22/dempsey/
- The Modernising Government white paper is at: http://www.citu.gov.uk/moderngov/whitepaper/4310.htm
- A description of the DNER is at: http://www.jisc.ac.uk/pub99/dner_desc.html
- The article, Z39.50 for All, provides an introduction to Z39.50 and is available at: http://www.ariadne.ac.uk/issue21/z3950/
- The Integrated Taxonomic Information System is at: http://www.itis.usda.gov/plantproj/itis/index.html
- The Diving Petrel occurs in and around the Antarctic, and appears upon at least two stamps which can be seen here: http://www.bird-stamps.org/species/13004.htm
- A graphical browser for bird taxonomy is at: http://habanero.nhm.ukans.edu/aves/default.htm
- OCLC’s homepage for the Dewey Decimal Classification is at: http://www.oclc.org/oclc/fp/
- The British Standards Institution’s UDC in Brief booklet has been made available online by NISS at: http://www.niss.ac.uk/resource-description/udcbrief.html
- ICONCLASS, the art world’s iconographic classification system, is at: http://iconclass.let.ruu.nl/home.html
- The Computing Classification System is browseable at: http://www.acm.org/class/
- Specification for resource description methods Part 3. The role of classification schemes in Internet resource description and discovery is a deliverable of the European DESIRE project, and is available at: http://www.lub.lu.se/desire/radar/reports/D3.2.3/
- RCHME’s Thesaurus of Monument Types was published in 1995, and is now available online from English Heritage at: http://www.rchme.gov.uk/thesaurus/mon_types/default.htm. Examples in text are drawn from the 1995 paper version.
- The mda Archaeological Objects Thesaurus is available online from English Heritage at: http://www.rchme.gov.uk/thesaurus/obj_types/default.htm
- Formal presentations given at the MODELS 11 workshop are at: http://www.ukoln.ac.uk/dlis/models/models11/presentations.html
- The Scottish Cultural Resources Network (SCRAN) is at: http://www.scran.ac.uk/
- The Central IT Unit of the UK Government’s Cabinet Office is responsible for much of the movement towards electronic Government, and can be found at: http://www.citu.gov.uk/
- The British Museum is at: http://www.british-museum.ac.uk/
- The Archaeology Data Service is at: http://ads.ahds.ac.uk/
- The SEAMLESS Project is at: http://www.seamless.org.uk/
- The HE Mall doesn’t exist yet, but is discussed on a mailing list at: http://www.mailbase.ac.uk/lists/hemall-discussion/
- The NKOS homepage is at: http://www.alexandria.ucsb.edu/~lhill/nkos/
- Autonomy is at: http://www.autonomy.com/
- CIDOC, the Documentation Committee for the International Council of Museums, is at: http://www.cidoc.icom.org/
Author Details
| Paul Miller Interoperability Focus UKOLN Email: p.miller@ukoln.ac.uk |