Building ResourceFinder
The RDN is a collaborative network of subject gateways, funded for use by UK Higher and Further Education by the JISC (though it is used much more widely). Each subject gateway, as part of its service, provides the end user with access to databases of descriptions of freely available, high quality, Web resources. As each resource described in the database is hand picked by subject specialists, following well developed guidelines, it is hoped that a resource discovered through the RDN will be of great value to an end-user.
RDN resource descriptions are held in metadata records that conform to the RDN cataloguing guidelines [1]. We provide a number of ways to access the records. A researcher with a specific subject in mind would probably want to visit one of the RDN gateway sites [2]. If they had a broader remit they may try using ResourceFinder [3], the RDN’s cross searching service that collates results from all of the gateways. Experience suggests that end users wish to use both approaches when using the RDN.
This article discusses the technology behind the RDN ResourceFinder service.
Approaches to cross searching
Each RDN gateway maintains one or more databases of metadata records. There are two possible approaches to providing a multidisciplinary cross search of all these databases:
- a distributed search, where a "broker" sends the same request to each of the databases in turn, retrieves results from them, and presents the whole set back to the user.
- a single database, where the records from each of the databases is pulled into a central store and indexed and served from there.
ResourceFinder initially used a distributed search approach, based on WHOIS++ and later Z39.50. Recent developments have seen a move away from the distributed search and ResourceFinder now uses a single "union" database of all RDN records.
Why a single database?
ResourceFinder is intended to provide a seamless search across all the gateway databases and present a mixed bag of results from any subject area. Because ResourceFinder merges all results from all databases the distributed model significantly slows response times. This is because any search is limited to the slowest database or network connection. In addition, because ResourceFinder has to wait for all the results from a given database (not, say, the first ten) and locally rank the complete set there is a processing overhead.
It is hoped that a single database would facilitate additional RDN services, the ability to start offering advanced search functions and a consistent cross browse interface across the RDN. For instance, by mapping the gateway specific resource types to the RDNT-1 [4] type list, we hope to be able to provide "Search by Resource Type" searches.
ResourceFinder
The current ResourceFinder architecture looks like this:
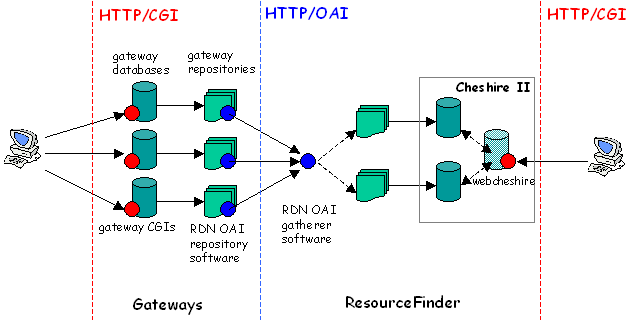
Figure 1
Each of the gateways maintains a live database that serves their Web interfaces. In addition to this they build a separate ‘repository’ of their records for gathering by the RDN. Records are gathered from each gateway to a single RDN repository. The records are then indexed and made available via ResourceFinder using the Cheshire II [5] software.
Towards a single database
There was a need within the RDN to switch to a single database supporting ResourceFinder fairly quickly. The main driving force was the slow response times we were experiencing from a distributed search. In addition, new gateways were starting to come online and were concerned at the technical effort involved in creating a Z39.50 target, essential for inclusion in ResourceFinder’s cross search. The proposed solution was the creation of a single database.
Around about the same time the RDN started to think about building a central database, the Open Archives Initiative (OAI) released a draft version of the OAI Metadata Harvesting Protocol (OAI protocol). The timing couldn’t have been better as this protocol provided the RDN with a ready made, standards based approach to its own metadata harvesting needs:
"The goal of the Open Archives Initiative Protocol for Metadata Harvesting (referred to as the OAI protocol in the remainder of this document) is to supply and promote an application-independent interoperability framework that can be used by a variety of communities who are engaged in publishing content on the Web. The OAI protocol described in this document permits metadata harvesting…" [6]
| UKOLN developed the Perl implementation of an OAI repository that is now in use across the RDN [7]. It consists of two scripts: one to covert the records from the gateway database format (ROADS, MySQL tables, etc.) to DC XML records, and the other an OAI front end to that repository. In this implementation, a repository consists of one or more directories on the local file system, containing metadata records as individual files. This approach makes generating a repository very easy as there is no need to interface with databases or the like. This approach (an approach similar to the way some RDN gateways provided Z39.50 targets by exporting all of their data into Zebra [9] databases) was adopted because of the need for rapid deployment at the gateways. RDN gateways use diverse database technologies: SOSIG, for instance uses (a fairly customised) ROADS, EEVL is based on its own MySQL/PHP solution. It would have taken time and effort for each of the gateways to develop their own OAI front-ends to their database. Much simpler to develop a simple script to export their data, especially when scripts existed in kind with the tools already developed to export data to Zebra. Part of the RDN OAI software included a sample ROADS to DC XML conversion script. It is not ideal however as it results in two copies of the data at each gateway: the live data, and the OAI repository data (see fig 1). Because of this there may be some inconstancies between the live data and the OAI data. Data inconsistency is unlikely to be any worse than the cross searching approach because Zebra indexes may not be updated in line with the live databases either. In practice the data inconsistencies are small and have a minimal impact on the quality of the service and what we lose through data inconsistency by creating a single database, is gained through the ability to make result sets more consistent with the gateways than was previously possible with a Z39.50 based cross search. Exporting the data into an OAI repository means we could (though currently do not) enhance or adapt the metadata as part of the export process. For instance we could make different attributes available in different OAI repositories for different audiences or licensees of RDN data. In the future there may be some convergence where the live database provides both Web and OAI protocol interfaces. Metadata HarvestingOnce the data is in the repository it is a simple matter for the RDN’s metadata harvester to access those repositories and retrieve all of the RDN records. This process is made even simpler by the OAI protocol and the open source tools developed to exploit it. The metadata harvesting process is automated by the RDN OAI gatherer developed using the OAI Perl libraries developed at the University of Southampton [10]. | The Open Archives Metadata Harvesting ProtocolThe Open Archives Initiative Metadata Harvesting protocol provides a mechanism for sharing metadata records between co-operating services based on HTTP and XML. The OAI Protocol allows metadata records to be shared between data providers (repositories of metadata records) and service providers (services that harvest metadata from the data providers). The protocol defines only six requests (known as verbs):
GetRecord and ListRecords support the retrieval of records from a data provider. Each record comprises three parts:
Data providers are allowed to support multiple XML metadata formats (provided they are encoded as XML). ListSets supports the grouping of records within a repository into logical groups. Records can be selectively harvested based on these sets or by the service provider asking for records corresponding to a particular range of dates. [8] |
The gatherer runs once a week at present, as the gateways update their own repositories with similar frequency. It may be that the frequency of harvesting increases if it inconsistencies between RDN and gateway result sets become too large. Recent experience suggests this only becomes a problem if a gateway adds lots of records in response to some world event and the records associated with it need to surface in ResourceFinder immediately. Situations like this are rare however, and can be managed manually.
The OAI protocol only allows for the retrieval of identifiers and associated records from the remote repository. It does not provide for local management of the gathered files. Because of this the RDN OAI gatherer provides additional functions to manage the removal of records. The gatherer has access to a list of local identifiers and compares that to the list from the remote service. Where identifiers exist locally, but not remotely, it is assumed that the remote site has removed that metadata record and so it is deleted automatically.
Metadata Indexing
The OAI protocol does not attempt to provide a searchable interface to a repository. In order to provide the ResourceFinder service the RDN has to index the metadata records and make the single database available via the Web. The RDN has adopted the Cheshire II system for this purpose.
You will notice from Fig. 1 that we have two copies of the repository and indexes. Only one of these repositories and indexes is live at any one time, the other being updated and rebuilt in the background. This is because we wanted to ensure that ResourceFinder remains live while we index the records. Our Web interface works with a virtual index that points at either one of these sets of indexes.
The indexing process is simple and fully automated. A script chooses the correct database to update and then deletes and adds records as necessary using the RDN OAI gatherer. We then run the Cheshire II indexer over the resultant repository (Cheshire II handles the native DC XML records without any processing) and this creates a set of index files. If the gather and indexing is successful the pointer is transferred from the live set to the updated set.
ResourceFinder itself is a CGI that uses Cheshire’s webcheshire Tcl interpreter to interface directly with the indexes of RDN records.
A Single Database
Having gathered all RDN records into a single database, the RDN is now in the position to offer both an OAI repository and a Z39.50 target to all of the RDN data or subsets of it. While we do not make our OAI repositories available outside of the RDN it is envisaged that we could offer access to RDN partners, and perhaps, the world.
Although we are using open standards, we are working in a closed environment; it would seem the OAI protocol is ideal for internal data sharing as much as "publishing" metadata.
References
- RDN Cataloguing Guidelines, Michael Day and Pete Cliff
<http://www.rdn.ac.uk/publications/cat-guide/>
- See:
BIOME
<http://biome.ac.uk/>
EEVL
<http://www.eevl.ac.uk/>
Humbul
<http://www.humbul.ac.uk/>
PsiGate
<http://www.psigate.ac.uk/>
SOSIG
<http://www.sosig.ac.uk/>
- See: ResourceFinder at the RDN
<http://www.rdn.ac.uk/>
- RDN Resource Types, Compiled by Pete Cliff
<http://www.rdn.ac.uk/publications/cat-guide/>
- See: Cheshire II Project Homepage
<http://cheshire.lib.berkeley.edu/>
- The Open Archives Inititive Protocol for Metadata Harvesting, ed. Herbert Van de Sompel, Carl Lagoze
<http://www.openarchives.org/OAI_protocol/openarchivesprotocol.html>
- Available at: ftp://ftp.ukoln.ac.uk/metadata/tools/rdn-oai/rdn-oai.tar.Z
- Protocol summary taken from An OAI Approach to Sharing Subject Gateway Content, Andy Powell
<http://www.rdn.ac.uk/publications/www10/oaiposter.pdf>
- See: IndexData’s Zebra
<http://www.indexdata.dk/zebra/>
- OAI-Perl Library, Tim Brody
<http://sourceforge.net/projects/oai-perl/>
Author Details
|