Cultural Heritage Language Technologies: Building an Infrastructure for Collaborative Digital Libraries in the Humanities
The field of classics has a long tradition of electronic editions of both primary and secondary materials for the study of the ancient world. Large electronic corpora of Greek and Latin texts are available from groups such as the Thesaurus Linguae Graecae, the Packard Humanities Institute, and the Duke Databank of Documentary Papyri, and in the Perseus Digital Library [1]. Because such large collections of primary texts have already been digitized, it is now possible to devote concerted effort to developing new computational tools that can transform the way that humanists work with these digitized versions of their primary sources. Further, with the emergence of digital libraries, it is possible for these computational techniques to be available not only to individual scholars, and not just as generic tools that are not packaged separately from the texts upon which they operate, but as an integrated part of a digital library system. The development of these sorts of tools for Greek, Latin and Old Norse texts are the core goals of Cultural Heritage Language Technologies project.
Cultural Heritage Language Technologies is a collaborative project involving eight institutions in Europe and the United States. The partners in Europe include The Newton Project and the Department of Computer Science, Imperial College, the Faculty of Classics, Cambridge University, the Istituto di Linguistica Computazionale del CNR, Pisa, and the Arnamagnaean Institute, University of Copenhagen. In the United States, the partners are the Classical Studies Program and Department of English, University of Missouri at Kansas City, The Perseus Project, Tufts University, The Stoa Consortium, University of Kentucky, Scandinavian Section, University of California at Los Angeles. The funding for this project has been provided by the National Science Foundation and the European Union International Digital Library Collaborative Research Program. The consortium has three major goals for its research. First, we want to adapt discoveries from the field of computational linguistics and information retrieval and visualization in ways that are specifically designed to help students and scholars in the humanities advance their work. Second, we hope to establish an international framework with open standards for the long-term preservation of data, the sharing of metadata, and interoperability between affiliated digital libraries. The ultimate goal of all of this work is to lower the barriers to reading Greek, Latin, and Old Norse texts in their original languages.
Core Digital Library Infrastructure and Corpora
The core digital library technology for this project will be the one used by the Perseus Digital library based at Tufts University. The Perseus system provides a general environment that can take any SGML or XML encoded text and present it to end users in HTML or other formats such as PDF. The system is a proven production environment that currently delivers approximately 8.5 million pages a month over the web. This system is also integrated with several knowledge management routines that identify elements such as geographic entities, dates, common word collocations and proper names and, it automatically generates maps, timelines, and hypertexts allowing users to explore relationships between texts in the system from many different perspectives. The digital library system also includes an integrated reading environment where all Greek and Latin words in the system are parsed and an automatically generated hypertext shows the lexical form of each word along with links to dictionaries, grammars, frequency, and search tools. The design of this system allows for new applications to be written as modules that can easily be integrated into the core architecture.
At the outset, the project will have several large testbeds that will be supplemented by new corpora that partner institutions will create in the course of this project. Our primary testbeds will be the parallel Greek-English and Latin-English corpora contained in the Perseus Digital Library. The Greek-English corpus for this study contains three hundred and thirty-four works written in Greek aligned with English translations. These works were written by thirty-three different authors and contain approximately 6.4 million words. Most of the texts were written in the fifth and fourth centuries B.C.E., with some written as late as the second century C.E. representing a wide range of genres, dialects and styles. The Latin-English corpus contains sixty-two works or 4.4 million words aligned with English translations. The Perseus Digital Library also provides a morphological analysis tool for the Classical Greek and Latin texts that can provide the lexical form for any instance of a Greek or Latin word within the corpus and also ‘unabridged’ lexica for both of these languages. At the same time, the Archimedes Digital Library Project – a research project jointly sponsored by the Deutsche Forschungsgemeinschaft and by the National Science Foundation to digitize early modern texts in the history of mechanics – have generously made their corpora available as a testbed for this project. In addition to these substantial corpora, three of our partners will also be digitizing new collections of texts for use in this project. The Newton Project at Imperial College is creating a corpus of Netwon’s theological and alchemical writings; the Stoa Consortium at the University of Kentucky will be digitizing a substantial body of early modern literary texts written in Latin; the University of California at Los Angeles and the Arnamagnean Institute will be creating diplomatic transcriptions of Old Norse texts that will be linked to high-resolution images of the original manuscripts.
Collaborative Infrastructure
A collaborative digital library environment involves co-operation among scholars and also among their software systems. In this project, we will create an infrastructure for collaboration between software systems based on the Open Archives Initiative protocols to make different collections from various digital libraries work together as easily as the texts within a single library [2, 3]. The technological platform for metadata sharing is the Open Archives protocol, developed by the Open Archives Initiative (www.openarchives.org) [4]. We propose to use the OAI protocol to share not only basic Dublin Core metadata, but also the more detailed metadata used in our digital library systems. For each text in a digital library, we must store catalog-level facts – title, author, and so on – as Dublin Core fields whose values are drawn from the header of the XML or SGML text. In addition to these fields, we add cataloging information about what abstract ‘text’ a particular version instantiates or comments on (e.g., is it an edition of Homer’s Iliad?) Thus, when a reader requests “Homer’s Iliad,” we can offer a choice among all available editions and translations of the text from any library that confirms . We are also able to supply notes from all available commentaries in all of the libraries in our consortium. In our system, these notes and citations are converted to hyperlinks so that when the referring text is displayed, and the cited text is in the same digital library, we simply make a direct link. When the cited text is displayed, we offer the reverse citation as a comment or footnote. (This system is described in [5] and [6].) We propose to extend this mechanism to texts in co-operating digital libraries. To do this, we will augment the existing citation metadata with “location” or “provenance” information, then distribute the metadata using the standard OAI protocol. When we make a link to a remote text, we will use the location information to construct the hyperlink in the correct form for any collaborating digital library that provides appropriate metadata via the OAI protocols.
Language Technologies and Scholarly Collaboration
Natural language processing is a mature field with well known effective algorithms for exploring linguistic features and extracting information from unstructured texts. Many of these technologies, however, are designed with a focus on commercial applications (i.e. amazon.com’s features that suggest other items that a purchaser might find interesting) or national security concerns (i.e. the Translingual Information Detection, Extraction and Summarization program funded by the United States Defense Advanced Research Projects Agency http://www.darpa.mil/iao/TIDES.htm). Given the presence of effective tools for other domains, the question we face as computational humanists is, which of these technologies are language dependent and, therefore, need to be optimized for cultural heritage languages and which of these technologies are most useful for users in the humanities? A baseline technology for these inquiries are morphological analysis tools. Simple stemming techniques (e.g. Porter’s algorithm) are not precise enough. In highly inflected languages, lexical normalization is required in order to have enough data to obtain statistically significant results. As noted above, the Perseus project already has these facilities for Classical Greek and Latin while the Istituto di Linguistica Computazionale del CNR, Pisa will develop a system for early modern Latin. and the University of California at Los Angeles and the Arnamagnaean Institute and will create a parser for Old Norse.
With parsers and corpora in place, the areas where we see the most potential benefit for students and scholars in the humanities are in the fields of information retrieval and visualization and in the study of vocabulary in context. One of our first areas of investigation will be in the areas of multi-lingual information retrieval and visualization. Multi-lingual information retrieval can be an extremely useful technology for non-specialist scholars and students who know a little bit of Greek, Latin, or Old Norse, but who are not able to form intelligent queries in the original language. People studying Homer, for example, could be very interested in the concept of heroic fame and reputation that plays such an important role in the Iliad. Working with only an English version of the text, they depend on a translator and the consistent translation of Greek words relating to fame and reputation. A multi-lingual information system, on the other hand, would allow them to locate important words, such as the Greek kleos, and then study the passages where these words appear without relying on translations. Given the state of our corpora and core technologies, we will focus our initial efforts on Classical Greek and Latin. A fundamental concern as we move forward, however, will be to develop common indexing formats so that we can scale these tools to Old Norse and early modern Latin as parsers and corpora for these languages come on-line. Indeed, a generalizable indexing format such as this one will allow the tools to easily scale to other languages and corpora that are outside the scope of our current project.
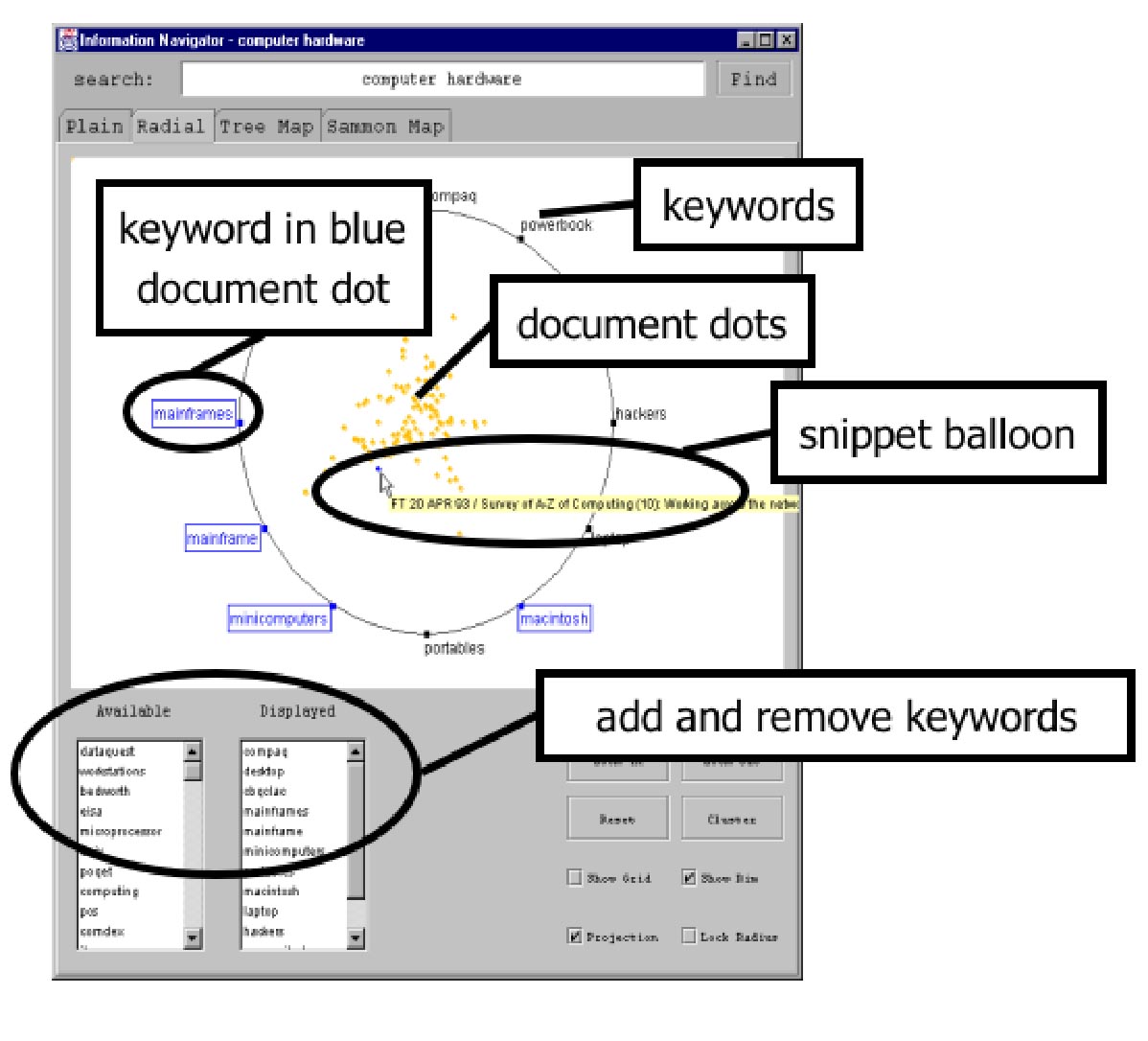
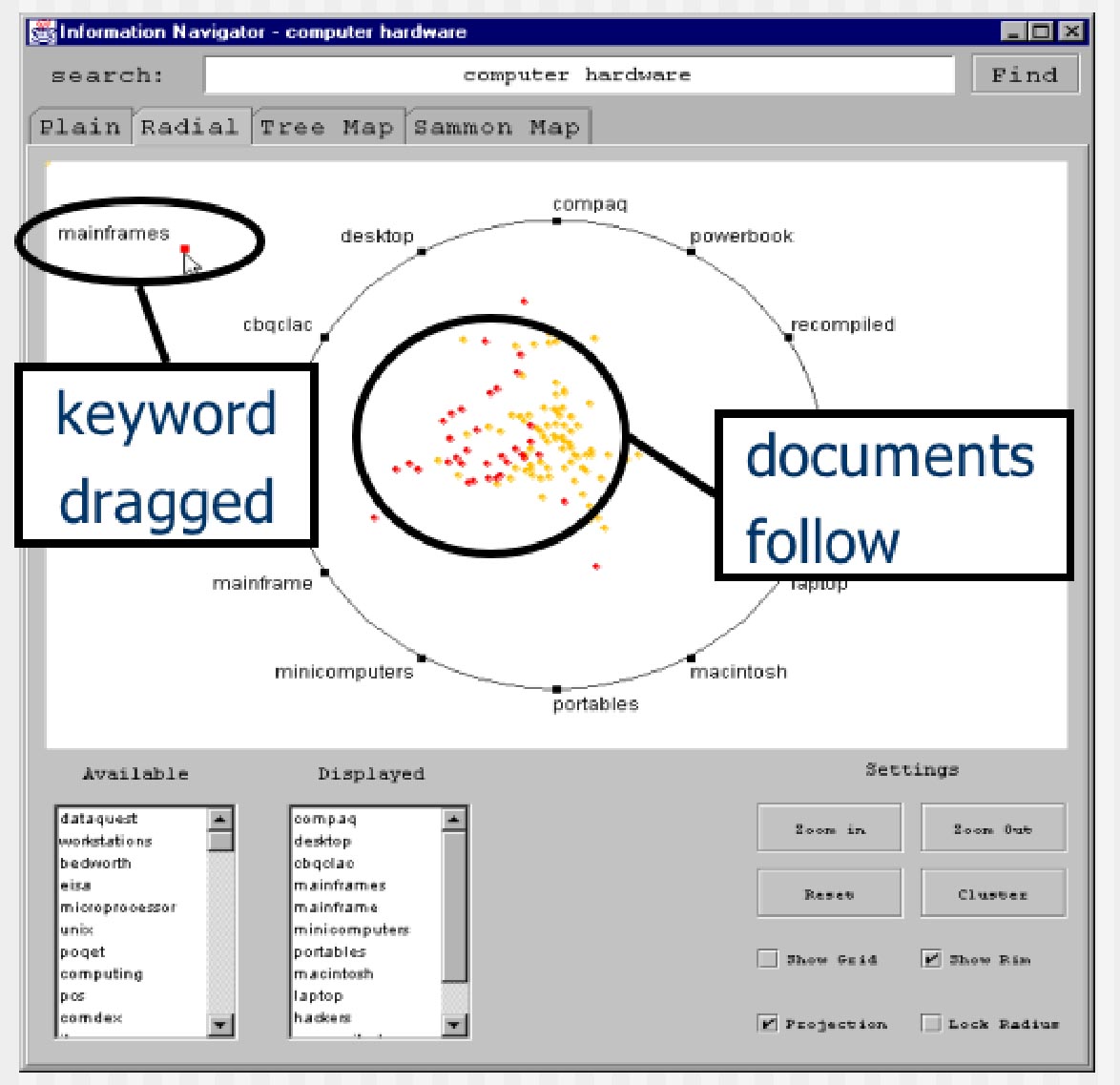
Closely related to our tools for multi-lingual information retrieval are facilities for information visualization. In digital libraries and library catalogs, search results are most frequently presented in a list that is either unranked or sorted by a metrics that are opaque and confusing to the end user. We therefore plan to develop a system that automatically identifies keywords; uses clustering algorithms to sort the repository subset into groups; labels those groups accordingly; visualizes them; and enables the user to focus on sub-clusters in the task of narrowing down a search. As seen in the figures below, this strategy shifts the user’s mental load from the slow thought-intensive process of reading lists to the faster perceptual process of pattern recognition in a visual display. By shifting the texts and query terms that are used with these tools, students and scholars can study, and draw conclusions from, the change in use of a particular word within a context over time, and even hope to detect the emergence of new concepts [11].
A second area where we see great potential benefit is for the study of words in context. With a parser that can reduce inflected forms to their possible lexical forms, we can develop applications that help users study texts more effectively. Even extremely simple applications such as word lists linked to a search engine can be useful for non-specialist users who are trying to study a text. The calculation of other measures such as word frequency, relative frequency, tf x idf scores, and measures of lexical richness can make these tools even more useful. To take only one example, the definition of a tf x idf score is designed to locate words that regularly appear in one document that do not appear very often in other documents within a collection. From the point of view of an information retrieval specialist, these are words that help uniquely identify queries and documents. If examined from the point of view of a language student, a list of words with a high tf x idf score contains the words that they are not likely to know from another context and that are, therefore, worthy of extra attention as they the read the text.
These simple tools are just the gateway to more complex and interesting tools as well. For example, we plan to develop a collection of tools that will allow for the discovery of subcategorization frames and selectional preferences of Greek, Lain, and Old Norse verbs within our corpora. Selectional preferences show the type of subjects and objects that usually appear with a certain verb. In English, for example, the verb “drive” often has an automobile or other passenger vehicle as its subject while the verb “drink” tends to take a liquid as its object. We can see potential selectional preferences in some of our co-occurrence data. For example, collocation data shows that the noun presbus (“old man, elder, or ambassador”) regularly co-occurs with the verb pempo (“to send”). What we cannot discover from co-occurrence data is the selectional relationship between this noun and verb. Are the elders sending things or are they the ambassadors being sent? Several algorithms for English should be adaptable so that we can make these sorts of determinations about Greek texts as well. Closely related to the discovery of selectional preferences of Greek verbs is the discovery of their subcategorization frames, or the syntax that regularly appears with a particular verb. While information about syntactic structures is sometimes included in dictionaries, grammars, and textbooks, it could be quite useful for readers to have a way to discover this information for any verb they might encounter in a text.
Computational methods can also be used to indicate if words or syntactic structures are associated more closely with a genre, an author, or even a work. We can see the value of these distinctions in both the frequency and collocation data that we already gather in the Perseus Digital Library. For example, the frequency data show that the word kleos (“honor, glory”) is used far more frequently in poetry than in any other genre of Greek literature and that Homer uses the word far more frequently than any other Greek author. Similarly, collocation calculations show interesting variations when different authors and genres are considered. For example, in Greek rhetoric, by far the most significant collocation of aner (“man”) is the word Athenaios (“Athenian”), pointing very strongly to the idiomatic way that speakers address juries in Athenian rhetoric, andres Athenaioi. This combination, however, is not at all significant in other genres such as drama or poetry and far less significant in other prose works. Similar distinctions can be made for calculations of selectional preferences, subcategorization frames, and semantic similarity, thereby providing richer datasets for the study of Ancient Greek vocabulary.
While these sorts of systems can produce a great deal of interesting information for users of the digital library, these results will never be entirely accurate. Further, scholars studying a specific text or topic will frequently want to correct, annotate, or extend the results of automated analysis. Although a few digital library systems allow for simple annotation or note taking, most systems require users to print search results or copy them to a word processor and then make their annotations by hand. Every time a scholar does this they are creating new data that has the potential to improve automated knowledge discovery procedures within the system; the new data thus created, however, is lost to the system because there are no mechanisms for reintegrating it into the system. This situation is untenable; the system should be constructed so that this expert knowledge can be used to improve the performance of the system. Therefore, our research partners at Cambridge will work with these linguistic tools as part of their work on a new Greek-English lexicon. We will create a system to capture their corrections and use this data to augment the digital library as a whole.
Conclusion
Our consortium is thus poised to take advantage of the large digital corpora of important cultural heritage texts that have been created in the past twenty years. We will create tools that will facilitate the reading of these texts, thereby, making it easier for large general audiences to read them. We will also create tools that will enable students and scholars to ask and answer questions about language usage that would be difficult or impossible to answer outside of an electronic environment. Funding from this grant will enable us to realize our vision of two new models for collaboration. These models are: a network of shared resources via the OAI at very low levels beyond metadata, and a model where the expert knowledge of user communities can contribute to and improve the tools within a digital library.
References
- See http://www.uci.edu/~tlg, http://scriptorium.lib.duke.edu/papyrus/ and http://www.perseus.tufts.edu.
- Andreas Paepcke, Chen-Chuan K. Chang, Terry Winograd,and Hector Garcia-Molina. Interoperability for digital libraries worldwide. Communications of the ACM,41(4):33Ð42,April 1998.
- Steve Hitchcock, Les Carr, Zhuoan Jiao, Donna Bergmark,Wendy Hall, Carl Lagoze, and Stevan Harnad. Developing services for open eprint archives: Globalisation, integration and the impact of links. In Proceedings of the Fifth ACM Conference on Digital Libraries, pages 143Ð151, San Antonio,Texas, June 2000.
- Carl Lagoze and Herbert Van de Sompel. The Open Archives Initiative: Building a low-barrier interoperability framework. In Proceedings of the First ACM-IEEE Joint Conference on Digital Libraries,2001. (forthcoming).
- Jeffrey A. Rydberg-Cox, Robbert F. Chavez, Anne Mahoney, David A. Smith, and Gregory R. Crane. Knowledge management in the Perseus digital library. Ariadne,25, 2000. http://www.ariadne.ac.uk/issue25/rydberg-cox/.
- David A. Smith, Anne Mahoney, and Jeffrey A. Rydberg-Cox. Management of XML documents in an integrated digital library. In Proceedings of Extreme Markup Languages 2000,page s 219Ð224, Montreal, August 2000.
- Jeffrey A. Rydberg-Cox. “Keyword Extraction from Ancient Greek Literary Texts.” Literary and Linguistic Computing (2002) 17.2:231-244.
- Jeffrey A. Rydberg-Cox. “A Prototype Multilingual Document Browser for Ancient Greek Texts.” National Review of Hypermedia and Multimedia (2001) 7:103-114.
- Jeffrey A. Rydberg-Cox. “Vocabulary Building in the Perseus Digital Library.” (with Anne Mahoney) Classical Outlook (2002) 79.4:145-149
- Peter Au, Matthew Carey, Shalini Sewraz, Yike Guo, and Stefan M. Ruger. New paradigms in information visualization. In Proceedings of the 23rd International ACM SIGIR Conference, pages 307-309, 2000.
- M. Carey, F. Kriwaczek, and S.M. Ruger. A visualization interface for document searching and browsing. In Proceedings of NPIVM 2000, Washington, D.C., 24-28 July 2000. ACM Press.
Author Details
| Jeffrey A. Rydberg-Cox Co-Director, Classical Studies Program Assistant Professor, Departments of English and Religious Studies University of Missouri, Kansas City Cockefair Hall 106 5121 Rockhill Road Kansas City, MO 64110 USA Email: rydbergcoxj@umkc.edu Web site: http://r.faculty.umkc.edu/rydbergcoxj |