Functionality in Digital Annotation: Imitating and Supporting Real-world Annotation
Long before the first Roman scrawled (possibly a term such as "detritus") in the margin of something he was reading, people had been making annotations against something they had read or seen, however uncomplimentary. It is more than likely that the first annotation occurred the moment the person making it was able to find a suitable implement with which to scrawl his or her opinion against the original. Annotating may be defined as making or furnishing critical or explanatory notes or comment. Whether positive or negative, implicit in the meaning of an annotation is the original text, image or other medium to which the annotation refers; and upon which that annotation is dependent for its full meaning.
In this article I would like to examine the the uses and characteristics of what we might term "pre-digital" or hand-written annotation before comparing them, in the context of digital annotation in a subject gateway environment, with the approaches in design that can be made in digital annotation. It is anticipated that the characteristics of analogue annotation will influence and even challenge the design of its digital equivalent. This will lead us to the consideration of annotation functionality from an essential standpoint, that of users. Finally we will be able to to consider some basic designs of more straight-forward annotation tools.
Definition of annotation in digital context
One form of a distributed digital environment would be a subject gateway. The gateway is designed to provide (usually registered) users with resources of agreed quality, grouped by subject, through a common browser-based interface. Access may be subject to authentication processes.
So a working definition of a digital annotation might be as follows:
A comment upon a digitally accessed resource as a whole, or the contents of a resource, and which itself can be digitally accessed as well as stored.
It would be equally reasonable to elaborate by stating that the annotation need not be stored in the same location as the original resource. (In the context of a distributed entity like a subject gateway, this would be most probable).
An annotation may apply to many different kinds of resources, text, image as well as other forms of Multimedia and can be applied at differing levels of granularity. For example, in the instance of a text document, an annotation could apply to the item description of the document, a sub-division of the document, a paragraph, passage or span of text right down to a single word as might appear in a glossary. Not all these levels would be necessarily appropriate for users and would certainly involve different functionality, but all could prove useful depending on the needs of the user.
Why do people annotate?
Whilst we take it for granted that annotations exist, what is perhaps less obvious is why people make and use annotations. It is important not to lose sight of the base document or original source when considering the purpose of annotations. As stated above, an annotation is worse than useless, indeed extremely frustrating, if it is not possible to see the reason why the annotation was written in the first place. However it is not an exaggeration to characterise annotation as a form of interlocution, i.e. a conversation between the original author and the annotator through the medium of their respective texts, or other media for that matter. After all, why do annotators annotate? It is because they wish to record, principally, their reactions to the base resource. In the context of publishing, of course, the annotations truly are a form of conversation with the author; annotation systems do exist to permit on-going conversations about the draft of a document being prepared for publication, as we will see in due course. But consider our example of the Roman writing ‘rubbish’ in the margin of the manuscript: he is most certainly addressing his remark to the author.
However, by and large, annotators are recording their comments in, say, books without any expectation whatsoever that the author will ever see them, (whereas of course the exact opposite is the case when we come to consider digital annotation). The words to emphasise in this instance would be "are recording". For even though the original annotator may have no expectation of his/her comments ever being read by another, such annotations can prove invaluable, particularly with the passage of time. In many instances this passage of time may last no longer than it takes to read the book or some sub-division thereof. Readers, just like software users, have differing motivations for their use.
Readers read for different reasons
Someone reading for pleasure may pencil in the margin an occasional note with nothing more than the vague notion that it will be amusing to remember the initial reaction to the text when it comes to a subsequent and conceivably far off reading. A student reading a book may be using annotations to provide, for example, brief plot notes throughout a narrative in order to obtain landmarks through a story, or key assertions in a polemical essay, etc. A researcher might well approach the same text, (conceivably the same that (s)he read as a student), with a somewhat different agenda. The annotations, (perhaps in a different colour), may be addressing answers to a specific enquiry the researcher has formulated. In writing his/her reactions, (s)he is now seeking to record to what degree the original work provides evidence to support or refute a finding or theory previously conceived. In this context the annotations possibly begin to form the bones of an argument either with oneself, or perhaps with contradictory material elsewhere. Where such contradictions or indeed agreements occur, the annotation is most effective when it is able to cite the comment in the other book together with the text to which that annotation refers. It is worth noting that whilst researchers' motivation and manner of annotation differ from the previously mentioned annotators, that element of conversation, in this instance more noticeably with themselves, is still central to the act of annotation.
It has been observed in this context [1] that wily purchasers of second-hand higher education text books eschew the neat nearly new copies on the shelf in favour of the much thumbed and weary looking versions. Their experience is that the latter tend to contain the largest number of annotations, annotations, moreover, which emanate from more than one author. Such copies consequently offer the purchaser a plethora of opinion and ideas in comparison with the near-pristine texts.
The annotation's audience
Whilst it is possible to argue that editors’and critics’ footnotes and commentaries are in fact annotations for the benefit of others, the main point is that handwritten annotations are not usually intended for publication. In effect, they have an intended audience of one; moreover, that one also happens to be their author. When we come to consider digital annotation, the motivation inevitably changes to a degree since the audience changes. This is because the anticipated audience has increased, albeit perhaps by only one; the annotator, conscious that the annotation will be read by another, will alter, however imperceptibly its content and style from that which (s)he wrote for personal use. The annotator is likely to improve the text in terms of clarity, supporting references, and, indeed even diplomacy and sensitivity. Indeed the greater the likelihood the annotation will be seen by strangers or outsiders to the domain in which (s)he usually operates, the more likely such enhancements, (and others, such as elimination or expansion of in-house acronyms or jargon), will occur.
Such enhancements are likely to require more space and clearer links. So it is just as well that the digital environment, with fewer restrictions on space and volume, is more capable of accommodating such improvements than its paper and binding equivalent. Having considered some of the original reasons for annotation in a pre-digital context and how their content alters with the annotators' motivation and audience, we might usefully consider some of the characteristics of annotation commonly experienced and consequently the challenges they represent to digital annotation design.
Problems posed by handwritten annotations and their digital solutions
We might usefully examine a few examples of real-world annotative behaviour which are illustrative of the benefits and difficulties which will confront anyone seeking to implement an annotation process in a digital environment. Let us consider what may confront a reader who comes upon annotations in a second-hand textbook or a library book.
Our earliest common experience of annotation may well be the cryptic, (though frequently anonymous) comments against a passage in a textbook. A common habit is to underline the text to be annotated; indeed such underlining may be the only form of annotation undertaken __ an indicator to the annotator only of an item of particular note. Where the annotator has only underlined the original text, there may well be no obvious reason for the annotation at all. The annotation is exclusive to that person. A digital system would be able to help to some degree. Firstly, and we will return to this advantage, it can automatically supply an author of the underlining or highlighting of the original text where the annotation system is distributed to others. Unless one were particularly interventionist, it is unlikely a digital system would insist on an annotation body or free text message, (though it could be designed to do so). However the automatic supply of a text editor for the annotator's thoughts related to the underlining or highlighting increases the likelihood of the annotator writing at least a short comment.
The alternative on occasions is no better for the new reader: the body or message text of the annotation may be clear, but the source, i.e the passage to which it refers may not. Does one assume, for example, that a one-line comment in the header of the book page relates to the topmost line of the page or the text of that entire page? Where a comment or opinion is written, it is often short in length; this is frequently because the annotator has only a narrow margin in which to write __ not without its benefits. Where the annotator does need to write more, (s)he may have recourse to writing the comment in the top or bottom margin, thereafter linking it in some way to the original text, for example by numbered asterisks. The situation can become even more frustrating where there are so many annotations that the referred text is unclear, or the content becomes confused. Just to make things worse, we can even predict that some of the solutions to these analogue obstacles may prove as difficult for the subsequent reader as the problems. If one uses scraps of paper on which to write lengthier annotations and inserts them in the relevant pages, all is well until the wind blows or the book is dropped.
Most of these difficulties would be addressed by the fundamental characteristics of a digital annotation system. The digital annotation system would automatically store and link annotations and sources with machine tidiness. As noted above, it is more than likely in a distributed system that annotations will be stored separately from the sources to which they refer. However, unlike the real-world equivalents, they would automatically hold information that links them effectively to the associated source. However, it is incumbent upon that system to display a clear association between annotation and source. But the potentially limitless capacity of an electronic writing space, indeed one that expands its viewing size to the later reader commensurate with the size of text inserted, would easily resolve the analogue annotator's problem of insufficient writing space. Moreover, it is worth taking into consideration the change that such expanded capacity may have upon the behaviour of annotators; an uncramped writing space may equally 'uncramp' their style and encourage them to be more expansive and, possibly, more informative. Equally important, there is no limit upon subsequent annotations relating to the original source or, for that matter, to the initial annotation. Clearly an example where the distributed nature of digital annotation presents a clear advantage.
Even a clearer annotation generally still lacks all or some of the following: an author, or author status, a date or time, and where the annotation relies on other text or supporting evidence, (e.g. "This contradicts his view in Chapter 3"), it may have no clear direct reference either. A further complication might be the annotations, (or even counter-annotations) of another anonymous party. It is worth remarking that a digital system would be able to record the date and time of the annotation action, the source, and give some indication of the person who initiated the marking. If it were deemed unacceptable in certain systems, the annotation could be rejected as giving inadequate content. Once again the advantage of virtually unlimited writing space would allow the annotator to quote, if desired, the text to which (s)he refers elsewhere; alternatively the functionality that permits the annotator to highlight a source could also be adapted to permit the highlighting of a reference item for inclusion in the annotation body as a hypertext link.
Some, but not necessarily all of the analogue difficulties may have been encountered; but they all serve to illustrate the difficulties that arise the moment annotations cease only to be read by their original author. It is outside that limited context that we largely need to consider annotations in the distributed digital environment.
Picking up on this aspect, we might therefore consider the challenge posed by any system of annotation that intends to have an audience of greater than one, and, conceivably of scores or hundreds of annotators and annotation readers. Irrespective of their number, what makes such multiple annotations unreliable is one's ignorance of the kind of person who made the annotation: expert? amateur? joker? authority? Who wrote the annotation probably ranks as more important than any other undisclosed information about it. In this regard an annotator is no different from an author or writer of papers. Understanding the authority with which an annotation is made can be a key determinant in users' behaviour when accessing annotations across a distributed system.
Questions of authority
In our initial consideration of real-world difficulties with annotations, we highlighted the problems posed by annotations that give little indication as to the authority of the annotator.
To illustrate this point more fully, we might consider the reviews written on books that appear in the pages of Amazon.com. These readily satisfy a definition of a comment on a resource, even where they are quite lengthy. Let us imagine that we are considering buying an expensive technical work on a little-known topic where a number of competing titles are available. Where a title is well known, there is an Amazon review, also sometimes reviews by critical journals; additionally there are reviews by people who participate in the Amazon reviewer profile and also those who do not. Our reactions as to the authority of the review vary, one might suspect, from category to category. Amazon's own review might be considered by some, to some degree, a little suspect as it has a financial interest in the book reviewed. The journal, supposedly independent, is more usefully judged on the basis of its prior reputation. The reviewers who leave a profile give clues as to profession, experience and education, though not necessarily always the degree of objectivity with which they have commented. Reviewers who leave no profile give clues in the content of their comment but ultimately leave no formal notion of the degree of their authority. Indeed unedited submissions may provide clues or red herrings by the quality of the language used; perceptive comments clothed in rather shabby syntax might wrongly be dismissed as invalid.
If the foregoing provides a qualitative look at the reviews provided by Amazon, a view based largely on provenance, it is worth briefly examining the quantitative aspect of Amazon's review information. When one selects a particular book from a list of competing titles, each selection appears with a scale of approval; 5 stars are presented and the level of approval is denoted by the number of stars that are coloured in. It is apparent that this rating system is fairly fine-tuned since it is capable of filling in fractions of a star. The feature that underpins this at-a-glance evaluation and renders it particularly informative is the accompanying text which indicates the total number of reviews received. Inevitably where a book attracts a relatively large number of assessents, the authority of the star rating increases. Perhaps mindful of the fact that in-house reviews may be criticised as self-serving, Amazon’s approach is to provide star-rated assessments that come from the public. Admittedly the background and therefore authority of such reviews are unknown.
However in Amazon’s case there is one more supportive feature that encapsulates the notion that annotations may annotate annotations and even vote upon them, i.e. rate them. Amazon publishes the results of its ongoing poll as to how many people out of a stated total number found an anonymous review, i.e. annotation, useful.
Certainly the application of two criteria ought certainly to allow a potential purchaser to identify a popular choice, (not necessarily the same as the right choice). Firstly has the title attracted a large number of reviews? Secondly, if so, is its approval rating average or above? If the answer to both questions is yes, the title may be considered a popular choice. Conversely if a title well past its initial publication date has attracted a positive rating but a small number of reviews, the case for its popularity is considerably weaker.
So where an annotator is not personally known by those viewing comments, any design may have to consider what the effect might be upon those evaluating the source against its annotations. The status of an annotator becomes increasingly important where the matter of authority looms large enough to become a factor in the user's assessment of the annotation. This will vary in importance depending upon the closeness or breadth of the world in which annotations are made.
It also provides a broad clue to what ought to determine the usefulness of these different aspects of digital annotation and their likelihood of inclusion: their potential value to their users.
Users with differing roles in a digital environment
Not for nothing does the consideration of a design for a digital annotation system revolve around its users. Whilst the software industry may not always react accordingly, it is increasingly conscious of the relationship between design failure and the inadequate identification of user requirements. Furthermore, the easiest route to such a failing is to omit altogether categories of users from the outset. We have already identified above how, in the pre-digital annotation environment, an apparently homogenous group of ‘readers’ turns out to have quite different motives for reading the same text or resource and consequently have quite different expectations and indeed methods of annotation.
By way of illustration, let us examine an example of another digital environment in which annotation could become an identifiable feature the moment one considers the different categories of people involved. A virtual learning environment or VLE is populated by a number of different actors. A VLE, as defined by JISC, (Joint Information Systems Committee [2]) constitutes " the components in which learners and tutors participate in 'on-line' interactions of various kinds, including on-line learning [3].
If we now consider a later section in the JISC circular it denotes the principal functions of a complete VLE and provides us with several clues as to the categories of users operating in the VLE, (emphases are mine):
14. The principal functions that a complete VLE needs to deliver are: controlled access to curriculum which has been mapped to elements (or 'chunks') that can be separately assessed and recorded;
tracking of student activity and achievement against these elements using simple processes for course administration and student tracking that make it possible for tutors to define and set up a course with accompanying materials and activities to direct, guide and monitor learner progress; support of online learning, including access to learning resources, assessment and guidance. The learning resources may be self-developed or professionally-authored and purchased materials that can be imported and made available for use by learners;
communication between the learner, the tutor and other learning support specialists to provide direct support and feedback for learners, as well as peer-group communications that build a sense of group identity and community of interest; links to other administrative systems, both in-house and externally [4] .
It is worth noting the variety of activities involved; a number of these could very reasonably be supported through the use of annotation.
The picture that JISC provides of a complete VLE indicates more than one role within this environment. The most obvious users of course are the students, the intended main beneficiaries. It is worth noting however certain wording which indicates, just as with our analysis of the 'readers' above, that students can operate in different ways or differ in their expectations or needs of the VLE. The term "controlled access" is the first clue to this. If students are not to be overwhelmed by material or to feel quickly out of their depth, there must be a progression through their course and its associated materials; in other words, course elements and resources are differentiated and access by students is controlled such that courses are encountered in an educationally rational order. Such differentiation consequently envisages students as different users by dint of their experience, previous knowledge and skills, ability and the subject or topic options they have made. Therefore whilst all students of the VLE follow a course through the curriculum, that course and therefore the population for which it is intended, may differ considerably.
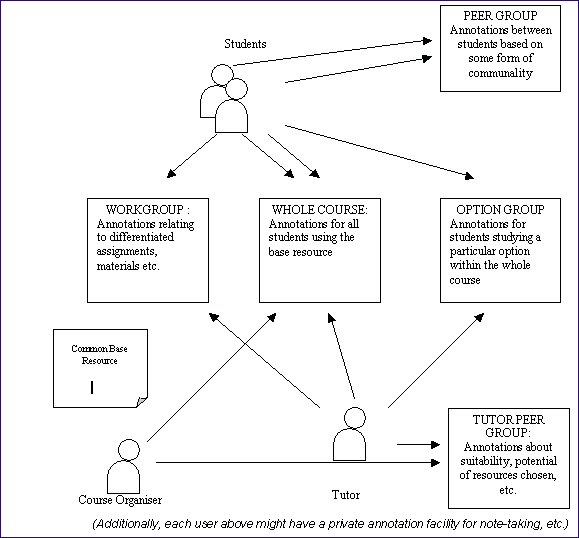
Figure 1: diagram: Differentiated use of annotations
(Additionally, each user above might have a private annotation facility for note-taking, etc.)
It follows that the guidance and support from another group of users, tutors, and even "other learning support specialists" will also differ. For example, a tutor offering historians an option on the development of Victorian Technology would annotate a document on the construction of urban sewerage systems with a different emphasis to the tutor offering the option on Public Health Policy. Nonetheless they could annotate the same document or resource in their own way and with equal benefit provided the annotation system was capable of distinguishing between the two sets of students and their tutors.
When considering users and the different roles they assume, we might also examine the phrase in the JISC circular: "as well as peer-group communications". Not only might tutors see the value of guidance and comment, i.e. annotations, for the benefit of a subset of the student body, but annotation can be of enormous assistance to members of a common subset, for example, engaged upon a group assignment, particularly where opportunities to communicate face-to-face may be limited, as may well be the case in a VLE. The opportunity to comment upon a resource or the assignment it engenders would definitely represent a facility designed to "build a sense of group identity and community of interest ".
There is no reason why the same facility could not be extended to the course tutors who share a common interest in the preparation and evaluation of course resources and other materials, (although within the JISC definition this function may operate more properly within the wider Managed Learning Environment (MLE) of which the VLE forms part, but no matter). Indeed, where tutors need to gauge common standards of evaluation, as in moderated assessment, items of students' work may become the base resource and annotations on them would be made by and for the tutors' peer group. Were the moderation process more formal, then there might be a need for the annotations to carry a formal scoring or rating system with the capacity to deliver statistics upon the whole body of students’ work. In this way the group of assessors would have statistics with which to benchmark each item. The advantages such an automated system would offer over its handwritten equivalent would be considerable.
Annotations and audience
What we can see evolving here is the whole issue of audience. For whom is the annotation intended? As we have seen above, annotations can be directed for the benefit of different groups of students as much as being intended entirely for 'public' consumption within the VLE, as in the case for example of an annotation giving general or introductory guidance. Indeed within the structure of a VLE, if there is a rationale for the creation of annotations for general or public use, as well as for subgroups based on common subject or background, there is also an argument for annotation for personal or private use.
We should not underestimate the value to students of such functionality; to tutors too, who would wish to engender a culture of documenting reactions and ideas associated with the base resource. Apart from the value of promoting a paperless study environment, such a private annotation facility saves time as students can include initial notes in subsequent work without need of transcription. Such private annotations tend therefore to seed comments. For example, an initially private reaction might be passed to a peer group for a reaction and having received support may go on to appear as a public annotation which benefits all.
A glance at the diagram above shows the degree of complexity a dynamic VLE might assume in its use of differentiated annotation. As this complexity grows it is inevitable that the exact nature of any given audience on an identical resource also becomes complex. Equally the larger the number of annotators, the more annotations will need to be prioritised in terms of their value to different users. For example, all users might have the option to view, create edit and delete their private annotations. A student might also view those directed at his/her course workgroup whereas a tutor might be presented with annotations from the all subgroups for which (s)he is responsible, and also conceivably from colleagues as mentioned above.
Where annotations on a record or resource begin to proliferate, then the information that attaches to any given annotation begins to assume increasing importance for the purposes of searching and display. It is worth considering the different types of information about the annotation, its metadata, that can be of use as numbers rise.
For example, the time of an annotation's creation is of importance even across the relatively short lifetime of a course module; what people think at the outset may alter considerably by the time they reach the module's conclusion. Every annotation needs to bear the reference to the resource upon which it comments, but the type of audience for which it is intended is a vital determinant in judging the value of the comment being made. The difference between an audience of first years and third years, for example, means that the comment made will be aimed at two quite different levels of understanding; references and information contained therein could be quite different.
Equally, as mentioned earlier, the subject or option emphasis would make a difference to a user's choice when searching for comments upon a resource. In effect where the role and status of annotators within a large system can vary greatly, the design of such a system would need to address what becomes another key issue: authorial status.
Annotations and their authors
For students at least, education is usually a fairly transient affair. The same can be true for tutors. As the number of users in our VLE increases, the greater the likelihood there will be that an annotator's name will mean less to a greater number of people. It therefore follows that metadata on an annotator's status could prove increasingly valuable. This holds equally true with another factor, mentioned earlier, which also tends to cloud viewers’ perception of an annotation: the passage of time, i.e. if public annotations on a resource are designed to persist beyond one cohort rotation. Any user in a hurry to find the most authoritative annotations on a resource could opt to filter out all but tutors' annotations provided it is possible to search on authorial status.
This capability greatly enhances the value of differentiated annotations since it encourages their use by promoting the means to allow users to prioritise their choices in the search for results and in displaying them. Moreover, were metadata on authorial status with regard to tutors to extend to their specialism or the option they offer, it allows viewers to consider their annotation in the light of the tutor's particular expertise. Such information would address in part one of the underlying weaknesses of much distributed information: the reliability and even bias of the author.
Annotations and metadata
Equally any student keen to learn of the published opinions of his/her year or peer group could set a search across that subset of users. Where a design offers to grant limited access to certain users, for example between members of a workgroup such that those in subgroup A may see all annotations made by its members whilst viewing none of those created by subgroup B, user status metadata would prove essential to the process. So a system using metadata to carry out such demands may be searching across a set of values such as:
Status=student;
Student=undergraduate;
Year=1;
Subgroup=A;
Course=History
Option=A:Public Health Policy;
In fact such metadata could be organised in a larger set that might divide across three main areas:
- information about the resource
- information about the annotation author
- information about the annotation
Consider this example:
| Resource | Annotation author | Annotation |
| Resource identifier | From: Name | Annotation Identifier |
| Resource proposer | Status | To: |
| No. annotations attracted | Course | Time |
| Rating received | Option | Date |
| Times annotated resource | No. annotations attracted | |
| Times annotated option | ||
| Times annotated course |
It is worth remembering that an annotation may become a sort of base document in itself since it should be able to attract annotations upon itself, a simple way of engendering debate about a specific resource.
The amount of metadata tabled above might appear unduly complex though not so if one includes the role in the VLE of an "other learning support specialist", namely the course organiser and resource provider. (S)he has set up the entire course and options for the tutors to use. Course organisers may be tutors themselves and have operated in consultation with all other tutors, but their role is overarching in terms of the course. Indeed they also constitute a further but hidden audience with regard to annotations. The numerical data in the table above could provide them with considerable assistance when assessing the usefulness of the resources they have placed on the virtual courses. An annotation system ,particularly operating at the resource or record level, represents a good indication of users' reactions. Even tutors, who will naturally provide a minimum acceptable level of guidance, will nonetheless find some resources more amenable to annotation than others. Minimal annotation from tutors and students may be an indication of a resource's relevance or usefulness.
It is possible to include in an annotation system's functionality a component with the specific task of requesting users' approval of the resource, just as with Amazon. The system design would then include the capacity to calculate the effect of each annotation's rating and providing information on averages, means and rankings, etc. This would go beyond the basic design of view, create, edit and delete annotations, but could prove useful.
Therefore an annotation system that takes account not only from whom a comment comes but also for whom it is intended, makes it possible for users to evaluate its content and authority to a far higher degree despite the heterogenous environment in which it was created. Finally, the inclusion of the numerical data suggested above can prove highly beneficial in permitting course organisers to see the overall picture about users' reactions to resources to add to their understanding of the different people who are annotating and their degree of experience and expertise.
Annotations as they relate to their source
If the example of the VLE provides us with a clearer notion of the users, i.e. that they can represent more than just one homogenous population, then we ought perhaps to consider to what annotations can refer. For just as an annotation must have an author and an intended audience, the other key relationship is with the base document or resource which has attracted the annotator's attention. We have already encountered comments upon whole resources, i.e. at document level. However that document may be composed not just of sections of text but also of illustrations, tables, diagrams and even audio or video clips, etc. It is possible that an annotator may wish to refer specifically to a constituent of such a document for example. There is therefore the matter of granularity: the level at which an annotation system refers to its base source. This could range from above document level, such as to a whole collection of resources, in the sense of libarary or archive collections but even also of a reading list which amasses a number of very large documents, e.g. books. An annotation can refer to a resource by annotating the record of that resource, i.e. a description of the whole resource as might appear in a results set following a search operation; in other words the annotation content could be a comment upon the accuracy of the record as a description, or seek to supplement its content, etc.
Heading towards the finer-grained end of the scale, annotations can refer to sections of a document, e.g. paragraphs, illustrations or supporting multimedia within the base document. Where close criticism is the requirement, then the annotation needs to make it clear to which spans of text, or just sentence or phrase, it is referring. By the time we come to annotation as a system of glossary support, the system is highlighting single words. Not surprisingly the design solutions required for these differing levels of granularity may also differ. A system operating at document level might well be able to use the resource or record url as the basis for its referral. A system highlighting spans of text would need a technology like XPointer [5] and a more complex approach to its base documents in order to deliver such a level of referral.
Nor should we forget, as intimated above with regard to possible metadata for annotations, that an annotation of itself can constitute a subject for comment and so a base resource. In such instances, it is important that the link between annotations on annotations and the base resource which attracted the first annotation is not lost. A whole thread of discussion is unlikely to begin if the original cause of the discussion is no longer accessible.
Naturally the complexity of the relationships between users of annotation in the VLE does not necessarily reflect a typical situation. It did however demonstrate the need to investigate the varying motives behind users even in a closed community with common aims. If one examined the scenario of say a subject gateway providing records of resources distributed across a number of servers and welcoming annotations from a far wider community of users, the relationships alter. Even where the gateway registers users or their institutions, much less might be known about them. Circumstances for a gateway or web site allowing free unregistered access to some or all resources whilst offering an annotation service, would be rather different.
While our working definition of annotation boils down to commenting upon an existing resource, inevitably the activity of the host will determine not only the kind of resources it holds but also what users will expect the annotation system to do. Though too complex to examine in detail, the example of a site or gateway offering archaeological maps and supporting pictures for comment will serve. It is reasonable for annotators to wish to comment on specific points on a map or photo, in efect operating at a very fine grained level of granularity. Though doubtless textual comment would also be desirable, users might want to point and append remarks. This would probably require some form of digital overlay with the capacity to draw lines, arrows and circles, etc. in much the same way as Paint ; and allow users to append text and perhaps other pictures, drawings etc. to those spatial indicators; whilst, all importantly, lest we forget, entirely preserving the original resource. A far more complicated implementation, but palpably the correct answer to the needs of the majority of its users on such a site. Without functionality of this order, the design might as well confine itself to email discussion.
Possible implementations
Simple annotation applications (1)
The most likely experiment with a pilot application will be an approach that does not impose a great deal of alteration to the existing subject gateway, since one hesitates to undertake an experimental addition if it might involve a great deal of re-writing of code to accommodate it. It is therefore important to consider the level of granularity of the annotation tool, since the finer that becomes the more involved the annotation tool has to become with the existing system. For example, an annotation system that permits comment upon spans of text in a base document represents a completely different and higher degree of complexity than one which operates by annotation of an entire resource or even the description of that resource. It is at that degree of granularity that an experiment could be undertaken.
One area that merits further investigation is a very minimal approach that obviates the need for any software production: the use of mailing list software. This would mean looking at the subject threads for the relevant resource. However such an approach would be incapable of wider functionality; it could not, for example, accommodate the inclusion of any form of usable ratings, i.e. a system to calculate the mean, average or otherwise of a series of grades or marks awarded by the annotators. Therefore such an approach would mean that there could be no extensions or development because of the very minimal basis on which it would be established.
However to provide an example of a possible approach, let us see how annotation could work simply with a resource or record. A user making a search of resources is provided with a number of results, each bearing a short description of that resource and three links. The first is to the resource itself, which (s)he uses in order to view the resource. This done the user navigates back to the list of results and clicks the other link, entitled "Comment upon this resource". Instead of being linked however to a full-blown annotation service, the user is presented with an email form, as is the case when one clicks on the email address on someone's personal page. In this instance however the resultant email form would not only bear the email address of the mailing list for these resource annotations, but also a subject line with some key information on the resource to be annotated, for example it's title, unique identifier, etc.
The annotation made, the user submits the annotation by sending the email to the list. On using the third link, "View annotations made on our resources", or similar, the user is presented with the archive of all mails/annotations written on the resources in that gateway. Therefore to find annotations on the same resource, the user will have to search the archive using the subject thread, which, as mentioned above, was pre-configured by the act of clicking the mailto link for that particular resource.
It would be fair to say that where the volume of users on a system were fairly low and therefore possibly even quite well known to viewers, such a simple model would operate fairly effectively since the number of annotations would not be excessive. Again, as is the case with any search results, such a model would be unlikely to require an elaborate system of filtering in order to bring the number of results down to manageable proportions. As mail archives can offer the option to search by author, date or even "most recent" mails, it is possible for persons monitoring the list, (we examine moderation elsewhere), to keep check easily upon recent additions to the list. It could be argued that were volume of traffic great enough, then one could create a mailing list for each resource, i.e. so that every mailto address were different for each resource. Whilst this would greatly simplify searching for relevant annotations, and free up the mailto form's subject line, the volume of traffic required to justify such a move would begin to push one in the direction of a more complex approach and the greater functionality it could offer.
Furthermore, the use of mailto is confined to Unix systems [6] . Mailto is a Mail gateway conforming to the CGI specifications. It can be used as a replacement for the mailto: URL scheme, with a form interface. Mailto was originally created in 1994, before the mailto: URL Scheme came into full use. Its primary and most commonly used role is in securely providing form usage for users on your system. Mailto allows users still to use forms by simply parsing all of the fields and emailing the results to the specified user, in this instance, the resources' common mailing list.
However, whilst this simple approach has the merit of avoiding the need for specific coding through the use of the mailto facility, it also presumes that the annotations will emanate from a closed community of users with a reasonable standard of browser. The greatest drawback is that the use of mailto does not conform to W3C HTML 4.0 specifications [7] and might represent a serious security flaw if the annotation system were accessible to virus writers [8]. This does not preclude the use of other mailing software which would be able to avoid these difficulties, but it is perhaps an example of how "quick and dirty" can be too dirty for comfort.
Simple annotation applications (2)
Whilst perhaps turning our back on a quick solution such as mailto, therefore, it might nonetheless be sensible to start from the same point as before, the record or resource description which provides a link that permits a fairly detached system of annotation to be created. This has the distinct advantage of avoiding the imposition of great alteration to the existing gateway resource retrieval system. As a minimum each resource description or record would need to offer an identical link to an annotation service.
That annotation service need not have to offer an enormous range of functionality. However to be of any value, it would have to offer users the option to:
- view all existing annotations on a record
- create their own annotation
- delete or edit their own annotation
Expressed in UML, this functionality can be represented as follows:
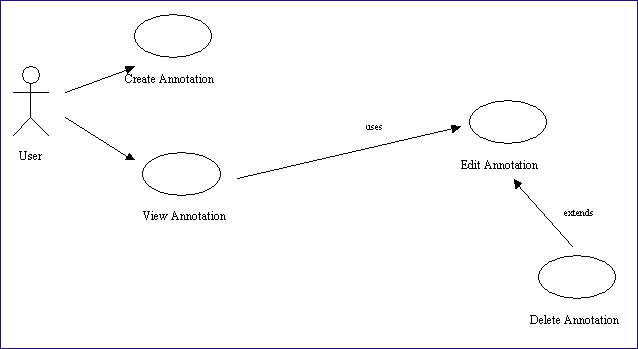
Figure 2: diagram: Use cases for basic design of simple annotation system
Another means of expressing the likely functionality of a simple annotation system is through screen prototyping as shown below. This approach allows one to envisage what exactly a user of the system might expect to see.
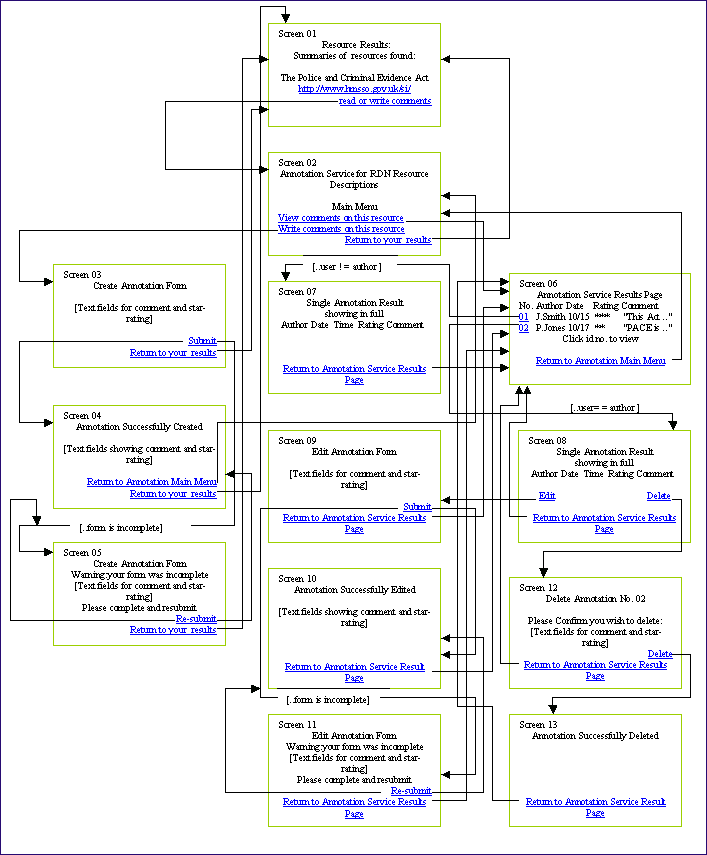
Figure 3: diagram: Map of Navigation between Screens in Annotation Design
Scenario
However the easiest way of understanding what a simple system might offer is to walk through a scenario of usage. Let us imagine therefore that a user receives a display of results from a search and is presented with one or more resource descriptions to inspect. Having done so, (s)he returns to the display of records.
- The user has the option to use a link to an annotation service, perhaps entitled "Read or write comments on this resource". Selecting the link brings the user to the Main Menu of the annotation service and the choice between viewing and writing a comment or annotation.
- The user opts to view and receives the display of an Annotation Service Results Page showing all the annotations that have been written on that particular resource by other users or even authors. (System simplicity imposes the limitation of viewing only annotations for the particular record viewed). The results are listed by author, date, star-rating accorded and the beginning of the annotation text. The user selects the annotation of choice and receives the display of the foregoing items plus the entire annotation text. The user then has the option to return and select another annotation or to return to the main menu.
- Returning to the main menu, the user opts on this occasion to stay with same resource but this time write an annotation of his/her own. The system therefore displays a form for the user's comment and star rating, say so many stars out of five, and on submission the form transmits the user's input together with other key data to the annotations database, provided the minimum input was present on the form and within range. Were this not the case, the form would be re-displayed with an error message. The information passed to the database includes not only the annotator's id and the date and time of creation, but most importantly the url of the record to which the annotation refers. All this information, together with an auto-created id number for the annotation itself is stored on an annotations database which is searched for annotations on a particular resource every time a user wishes to view.
- Whenever the user opts to view an annotation that (s)he created, the system will offer the option to edit or delete it using another form with the original contents present. The system will delete or update the annotation on the database accordingly.
It should be emphasised that this is very much a basic design; it simply offers a basic functionality. At base the system maintains a database of annotations and requires a means of inputting data from the annotators, which could be accomplished by CGI and HTML forms, and the means of storing annotations effectively on a database so that they can be searched against a resource id.
However simple this approach might appear, it has one overwhelming advantage over the simpler solution of using existing mailing software: it is capable of enhancements. For example, it would be possible to offer the user a number of ways of displaying the results during annotation viewing, chronologically rather than by author, a summary or subject line could be offered so that in effect users could begin threads on a particular annotation. The failure to apply any analysis of the star ratings that a resource has attracted could be rectified within the scope of this basic design by collating the results on the database and providing some averaging or ranking facility right across the resources annotated. Something like the latter option is entirely feasible since it is able to seek data right across the database.
Therefore whilst quick solutions may exist, it is reasonable to argue that the existence of a stable repository in the design such as a database provides the minimum basis upon which it is possible to add greater functionality to a design.
Simple annotation applications (3)- auto-moderator
As has been mentioned above, whilst there may be items of functionality which can remain entirely elective, there is also functionality that is imposed upon the system by the very nature of the community or volume that it serves. It was noted with regard to the quick solution of the use of mailto: as a rapidly installed annotation system that its use could only be advocated in a small close-knit community with similar if not identical equipment. This is an example of how the nature of the users determines the limitations of the annotation system solution.
The following extension to the basic design serves as an example of how the size of the population with access to an annotation system imposes the adoption of an item of functionality in order, in effect, to protect the effective operation of the basic annotation system. In this instance, a large number of users of a system who have no common goal or identity means that some contributors of annotations may be tempted to post inappropriate content that might cause offence to other users. The most obvious example would be obscene language. Small user communities, where everyone is known to other users, rarely encounter such problems; where the number of unknown contributors increases, this risk grows commensurately. Therefore a system of control such as moderation imposes itself in order to police and maintain the use of the basic annotation system.
In this instance the UML model of such an extension to the basic design would look as follows:
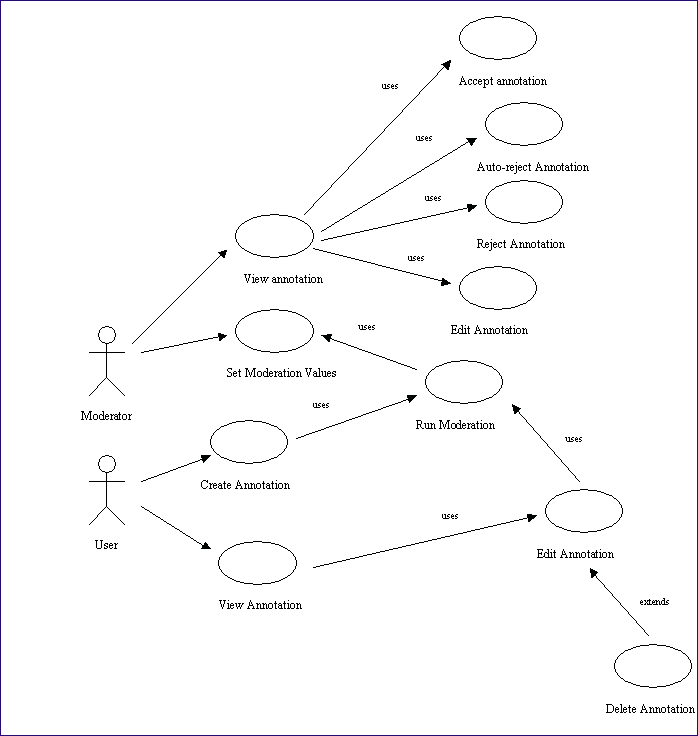
Figure 4: diagram: Annotation Use Case Main Model
However, once imposed, complications may be occasioned by the number of annotations involved. It is largely unlikely that any one person will devote their entire effort to moderating even a large volume of annotations on a frequent basis. Consequently a slightly topsy-turvy regime begins to operate: in order to ensure that no inappropriate annotations become viewable, annotations must await the attentions of the moderator before being certified viewable. In effect the contributors of the 99% of annotations that do not contravene the AUP (Acceptable Use Policy) are obliged to await clearance in order to police the 1% that offend against it. The situation becomes all the more unacceptable when the moderator goes on leave, etc. and annotations begin to back up.
The response to such a problem would be an automatic system that permits the immediate viewing of almost all "innocent" annotations whilst withholding from view the small percentage that contravene the AUP. Such an auto-moderator would be designed to vet the provenance and content of all annotations. Using a set of criteria that can be loaded and configured by the human moderator or Moderator, the system would assign values to all elements in an annotation that appear to represent a threat. A simple example would be a fairly high value being registered at the presence of an obscene word. Such a high value might alone bring about the system reaching its threat threshold, i.e. the point at which that particular annotation will no longer be automatically viewable. The same outcome might occur after the accumulation of points awarded to possibly milder language but also a "riskier" domain name in the email address than say ".ac.uk", as an example.
An important aspect of such an auto-moderator would be the flexibility accorded the Moderator in what terms (s)he might load into the list of criteria, the individual values of threat they attract, and the threat threshold or degree of tolerance under which the system generally operates. The Moderator could therefore render the auto-moderator more sensitive to, or less tolerant of, threats than usual.
Whilst the system would ideally come with a set of criteria pre-loaded, the Moderator, in the light of experience, could add to the threat criteria and refine the values (s)he accords them. There would however also be a set of threat criteria pre-loaded to deal with a danger that the Moderator might not have anticipated: virus attacks and other malicious contributions. It is not possible to devote any great space to this aspect. However if the basic system of annotator form validation does not address this problem because the threat is not perceived great enough to warrant it, (given the community of users), then at the point a moderation system becomes necessary for the reasons already stated, so does a means to check on such forms of attack.
Even a simple design could include certain threat criteria that would deal with a large number of such malicious items. For example, an attacker including an executable script in the body of the annotation content would need to use angle brackets. The criteria values could be configured to accept, say three such brackets before hitting the threat threshold, so as not to disadvantage, for example, mathematicians' annotations, but anymore would mark the annotation as a major threat and cause it to be quarantined.
Another aspect of malicious use, albeit not a virus threat, would be the posting of url's which lead to inappropriate web sites. The simplest solution would be to exclude all such site recommendations by creating a high value against a criterion of "http" in the annotation text. However, once again, this seems completely unfair on the overwhelming majority of contributors who wish to recommend sites or resources by citing a url. Therefore the auto-moderator's pre-loaded criteria should be configured to tolerate url's that include reassuring elements such as ".ac.uk", ".edu" etc., whilst apportioning high threat values to url's about which a Moderator would feel less complacent.
It is important to recognise the value of the flexibility accorded the Moderator by such a design. The ability to add threat criteria on the basis of experience or as a reaction to a sudden perceived threat should permit some fine tuning of the auto-moderator's capability. It would be reasonable to say that the system and the Moderator have reached the peak of performance when only a small percentage of blameless annotations are being withheld from immediate viewing and absolutely no inappropriate annotations are escaping detection.
Conclusions
In conclusion, this article has considered some common issues to the development of digital annotation by going back to pre-digital characteristics in order to take account of users' expectations and behaviour. One issue has been the relationship between the type of resources held and the annotation functionality that is appropriate. However perhaps even more important is the need to consider where the system is working and the community it must serve, whilst avoiding the pitfall of grouping too closely together the individuals in that community in terms of their motivations and differing use at different times. This is something to be borne in mind if one wishes to avoid placing all those individuals en bloc and imposing a "unique option", or Hobson's choice. But just as excessively fine-grained granularity can turn out to be irritating for users who are content to work with much coarser grained anchors, so can over-complex annotation tools burden users unnecessarily. It is worth recalling an observation made by one investigator [1] that most annotators just wanted to underline. That is to say, purely for their own benefit. So audience is as much a consideration in design as an annotation's authorship, in fact probably more so. It is perhaps sensible to recall that just because something can be designed, it does not follow that everyone will want it.
This article perhaps appears to demonstrate the extremely long road taken by the human race from the marginal scrawl to the worldwide transmission of, or access to, structured analysis with supporting links unencumbered by any of the failings of the entity it actually analyses or annotates. However it is worth remembering that even digital annotation is still very much a human process and consequently subject to the vicissitudes and shortcomings that can characterise human thought and action at times. In common with most successful technological innovations, it will be the annotation system designs that most closely consider human flaws and, in particular, needs and motivations, that will give most satisfaction.
References
- Marshall, C. "Annotation: from paper books to the digital library" in Proceedings of the ACM Digital Libraries '97 Conference, Philadelphia, PA (July 23-26, 1997) http://www.csdl.tamu.edu/~marshall/dl97.pdf
- The Joint Information Systems Committee http://www.jisc.ac.uk/
- JISC Circular 7/00 http://www.jisc.ac.uk/index.cfm?name=news_circular_7_00, Definitions, item 8
- JISC Circular 7/00 http://www.jisc.ac.uk/index.cfm?name=news_circular_7_00, section 14
- XML Pointer Language (XPointer) Version 1.0 http://www.w3.org/TR/xptr/
- Mailto 1.6 http://www.roguetrader.com/~brandon/Mailto/
- HTML 4.01 Specification http://www.w3.org/TR/REC-html40/
- The Mythical Mailto: http://www.isolani.co.uk/newbie/mailto.html
Further Reading
- Christophides V. "Community Webs (C-Webs): Technological Assessment and System Architecture" (2000), ch.4 http://citeseer.nj.nec.com/christophides00community.html
- Denoue, L. "Adding Metadata to improve retrieval Yet Another Web Annotation System" Feb 1999
http://www.univ-savoie.fr/labos/syscom/Laurent.Denoue/publications/TR1999-01.pdf - Denoue, L, Vignollet, L. "An annotation tool for Web browsers and its applications to information retrieval" (2000) http://citeseer.nj.nec.com/denoue00annotation.html
- Laliberte, D., and Braverman, A., "A Protocol for Scalable Group and Public Annotations." Proceedings of the Third International World Wide Web Conference, Darmstadt, Germany, April 1995.
- Marshall, C.C. "Toward an ecology of hypertext annotation" in Proceedings of Hypertext and Hypermedia '98 (Pittsburgh PA, June, 1998), ACM Press, 40-49. http://www.csdl.tamu.edu/~marshall/ht98-final.pdf
- Doug Rosenberg and Kendal Scott, "Applying Use Case Driven Object Modeling with UML", 2001, Addison-Wesley ISBN 0-201-73039-1
- Wilensky, R. "Digital Library Resources as a Basis for Collaborative Work" JASIS Volume 51, No. 3, February, 2000 Robert http://citeseer.nj.nec.com/wilensky00digital.html
Acknowledgements
Research for this article was undertaken as part of the research activity for the IMesh Toolkit Project, a project for providing a toolkit and architecture for subject gateways, funded by JISC/NSF. The author would like to acknowledge the invaluable support of Leona Carpenter (former Technical Development and Research Officer, UKOLN) in the development of this article.
Author Details
Richard Waller Information Officer, UKOLN |