Metadata Wanted for the Evanescent Library
This event was organised jointly by UKOLN and the National e-Science Centre (NESC) [1]. Liz Lyon, Director of UKOLN, gave the introduction, reminding us that this was the second UKOLN-NESC workshop. The first happened about a year ago, bringing together the digital library and Grid computing communities for the first time. The presentations were as follows:
- Building a Semantic Infrastructure - David De Roure
- Why Ontologies? - Jeremy Rogers
- Publishing and Sharing Schemas - Rachel Heery and Pete Johnston
- Implementing Ontologies in (my)Grid Environments - Carole Goble
- Knowledge Organisation Systems - Doug Tudhope
- Concluding Remarks - Carole Goble
Building a Semantic Infrastructure
In his introductory talk, Building a Semantic Infrastructure, Professor David De Roure of the University of Southampton, provided a history lesson at a gallop on the Grid and the Semantic Web. He began by attempting to dispel the myth that the Grid is all about huge amounts of data, high bandwidth and high performance computing. This is no longer true. Science is a ‘team sport’, and the Grid facilitates this. What the Grid is really about is resource sharing and coordinated problem solving in dynamic, multi-institutional virtual organisations. He referred to the Open Grid Services Architecture (OGSA). The old problem was lots of different computers; the new problem is lots of resources of various types. The holy grail is semantic interoperability, and the domain is not only research, but encompasses e-learning also.
Professor De Roure quoted Tim Berners-Lee on the Semantic Web: ‘The Semantic Web will be a space in which data can be processed by automated tools as well as people.’
He presented a 7-layer architecture of the Semantic Web:
Trust |
Proof |
Logic |
Ontology Vocabulary |
RDF |
XML + Namespace |
URI/Unicode |
He then went on to spend some time describing OWL (‘Web Ontology Language’, which spells OWL, he reminded us, in the same way that Owl in Winnie the Pooh spelt his own name). He posed two critical questions:
1. Where will the metadata come from?
2. Where will the ontologies come from?
The answer must involve collaboration between the digital library and knowledge representation communities.
Moving on to the Semantic Grid, the core problem was quoted as being the need for flexible, secure, coordinated resource sharing among dynamic collections of individuals, institutions and resources. Metadata is crucial to the Semantic Grid. He went on to present a useful diagram showing the Semantic Grid as being both highly based in computation and highly dependent on semantic technologies.
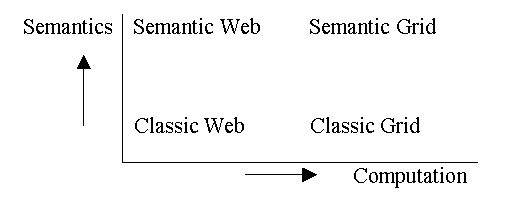
Figure 1: Convergence of Grid and Web
Web and Grid convergence is now the leading edge of the discourse. He concluded by saying that the goal is to accelerate the scientific process and not just scientific computation: this is the reward which will motivate the Semantic Grid.
Why Ontologies?
Dr Jeremy Rogers of the University of Manchester then gave an excellent presentation from the perspective of medical informatics, on the topic Why Ontologies? His e-Science project is called CLEF [2]), which has the goal of extracting text from clinicians’ descriptions of patient cases, and using ontologies to make deductions from these. He began by describing the differences between quantitative and qualitative data, giving examples from medicine. The history of description in medicine is approximately 400 years old. A publication called the London Bills of Mortality appeared every Thursday from 1603 until the 1830s. In the 1860s, William Farr took these Bills and attempted to regularise them, which in time became the International Classification of Diseases. Librarians entered the picture in 1900 with MeSH, and Elsevier arrived with EmBase in the 1950s. There are now many different medical classifications, and many projects trying to address the problems with them. Two of the largest and most comprehensive schemes are SNOMED and UMLS (which has 1.8m different medical concepts). To illustrate the rate at which descriptions of diseases and conditions are growing, Jeremy informed us that between 1972 and 1999 the number of possible descriptions of pedal cycle accidents grew from 8 to over 900.
We are good at measuring and describing things in a simple way, but not at the capture, integration and presentation of descriptive information. He described how case notes could be marked up differently by different GPs using the same scheme (XML). Computers have therefore been unable to help, because they are built by people for interpretation by people. Hierarchies (borrowed from librarianship) cannot easily be computed, and terms cannot be understood by machines. The solution is formal ontologies (‘Let the electronic brain take the strain’) which can be used as the basis for inference and synthesis. In a list of caveats, he counselled that logic however will not cure all ills. There are ‘ontological bear traps’ (e.g. ‘bladder’ is an ambiguous term). Rigour of build is no guarantee of rigour in use. He concluded by saying that there is a need to describe the world, which is very different from measuring it.
Publishing and Sharing Schemas
Rachel Heery of UKOLN spoke on Publishing and Sharing Schemas. She began by explaining that the motivation for looking at registries is the proliferation of metadata schemas, and provided some helpful definitions in an area where terminology is not yet clearly understood, at least by librarians. She gave a description of a schema as ‘a structured representation that defines and identifies the data elements in an element set.’ A schema provides an authoritative declaration of semantics, and defines the formal representation (RDF or other language). An element set is ‘a coherent bounded set of elements (terms) formulated as a basis for metadata creation.’ Both MARC and IEEE LOM are element sets. An application profile is ‘an element set optimised for a particular local application.’ There are a large number of DC application profiles. Application profiles may use elements from different element sets.
Schemas are generated from digital libraries, open archives, enterprise portals, e-commerce, e-science, rights and conditions of use, etc. There is a need in all of these to facilitate data exchange, share and reuse metadata, and use common tools, while allowing for extensibility and localisation. Her project has been seeking to encourage ‘declaring and sharing’ of data elements, element sets and application profiles. The initial focus has been on navigation, supporting schema evolution, providing mappings and annotations. Users might be software (e.g. metadata editors, validators or conversion tools) or humans.
Registries may be distinguished by their collection policies. Design choices have to be made (e.g. thin registries - containing links, and thick registries, which are databases). Decisions need to be made on whether schemas are created centrally or in a distributed way, and whether access is by humans or software. Also, the decision must be made whether the registry is a shared collaborative web tool, or a web service.
In the digital library world there are three well-known registries:
- DESIRE registry (SCHEMAS Registry, sharing schemas and application profiles)
- MetaForm (database of DC crosswalks, based in the University Library at Göttingen)
- DCMI Registry (authoritative specification of DC current element sets, hosted by OCLC)
The Metadata for Education Group (MEG) has a JISC/BECTa-funded project to provide an interactive environment for schema registration. Metadata schema registries are just part of wider work going on in registry creation at present. Two other examples which Rachel gave are the national Health Information Knowledgebase in Australia, and the US Environment Protection Agency’s Environmental Data Registry. There is also the xml.org registry, which offers a central clearinghouse for developers and standards bodies to submit, publish and exchange XML schemas, vocabularies and related documents.
Rachel then went on to consider how this relates to ontologies. Simple ontologies have been described as having three distinct properties:
- Finite controlled (extensible) language
- Unambiguous interpretation of classes and term relationships
- Strict hierarchical subclass relationships between classes
Her conclusion was that there are commonalities between metadata and ontology initiatives. However, the scale and complexity is different. Ontologies focus on semantic relationships and the delineation of knowledge space, whereas metadata schemas concentrate on descriptions and on instantiations of objects.
Her UKOLN colleague Pete Johnston continued Rachel’s theme, describing how the MEG registry tool works. It reads machine-readable descriptions of metadata vocabularies, indexes them and provides browse/search interfaces for humans and software. The registry data model is a simplification of complexity, providing a basis for comparison. It is based on the DC ‘grammatical principles’, subsuming elements, element refinements and encoding schemas. It is also based on application profiles, which give rules for how elements are used. This is very useful work in formalising the work going on internationally in metadata use. It also seeks to encourage the re-use of existing element sets, rather than the creation of new ones. He showed how application profiles can be created simply by means of a ‘drag & drop’ tool.
Implementing Ontologies in (my)Grid Environments
Professor Carole Goble of the University of Manchester gave a presentation on Implementing Ontologies in (my)Grid Environments. Her opening statement gave heart to the librarians present: ‘The Grid is metadata-driven middleware’. Ontologies are prevalent and pervasive for carrying semantics. What can the Grid offer as a mechanism for ontology and schema delivery services? The Grid now seeks to empower the user or a process to discover and orchestrate Grid-enabled resources as required. This implies cataloguing and indexing available resources using agreed vocabularies - but what is being described is not documents, but software components and data fragments. The Library which the Grid community recognises is evanescent: ‘the library is now an arbitrary and disappearing set of fragmentary resources.’ The metadata requirement is not simply content (as librarians would understand a requirement for cataloguing metadata), but also for its frameworks - the schemas and ontologies which must populate the digital order. However, the Library is still required to manage the permanent resources for which it already has the metadata maps: ‘In the end, biologists go and read a whole load of papers.’
Using the example of biologists whose experiments are increasingly done in silico, she made the observation that Grid work is data-intensive, not compute-intensive. Experiments on the Grid have a life cycle which begins with forming experiments and moves through executing and managing them to providing services for discovering and reusing experiments and resources. The architecture for this is essentially service-based. Services have to be found, match-made, deregistered, linked together, organised, run and executed. This architecture gives rise to a whole range of metadata problems: there is a need for shared schemas and registries. The underlying technology is Web Services-based, and the services belong not to myGrid, but to the world, and are registered in service registries, expressed in RDF-based UDDI. The descriptions are of the services at the atomic level, of third-party annotations of services, of quality of service and ownership. Registries must be able to answer questions such as ‘What services perform a specific kind of task? What services produce this kind of data? What services consume this kind of data?’. Things are described by their properties, and the classification is then assigned by the inference engine. ‘In the Grid we end up with tiers of abstraction for describing services.’ The world is also one of multiple data types - conceptual types, plumbing syntax, biological data formats, MIME types etc. - all of which have to be associated.
Knowledge Organisation Systems
Dr Doug Tudhope of the University of Glamorgan described Knowledge Organisation Systems (KOS). He classified KOS under three types: term lists (e.g. authority files, gazetteers, dictionaries, glossaries), classification and categorisation tools (e.g. Library of Congress and Dewey Decimal) and relationship schemes (e.g. thesauri). Ontologies, and semantic networks, were considered to be relationship schemes. Thesauri employ three standard relationships between concepts: equivalence, hierarchical and associative, whereas ontologies employ higher-level conceptualisation, defining relationships formally and deploying inference rules and role definitions. The KOS legacy is large multilingual vocabularies, indexed multimedia collections and scientific taxonomy initiatives. They have been created on the basis of peer review, and by following standards, but they are losing value in the digital world because they cannot explicitly represent semantic structure. Semantic Web technologies now afford an opportunity to formalise and enrich KOS systems. There are some projects now in existence, for example, to represent KOS in RDF/XML, and the NKOS Registry is a draft proposal for KOS-level metadata, based on Dublin Core. These initiatives give rise to the possibility of cross-mapping between different KOS systems, such as is being explored in the Renardus Project.
He went on to discuss the research issues faced by KOS. What services for digital libraries and the Semantic Grid may be built on them? Can traditional library-faceted classification techniques and knowledge representation foundational concepts be made into complementary approaches? The UK Classification Group has recently extended Ranganathan’s set of five fundamental categories to: entity, part, property, material, process, operation, product, agent, space and time. These are now used as the basis for several industrial KOS. The difficulty, however, is that the synthesis rules for facet combination lack formal expression. However, in the ontology world, foundational concepts and relations employ similar fundamental categories, logically expressed and axiomatised, and there is potential there for faceted classification and ontologies to join forces in creating new automated means of representing knowledge.
There is work in progress at present to link Digital Library entities (collections, objects and services) to KOS entities (concepts, labels and relationships). Visualisation tools are also being built which can use the rich semantics embedded in KOS. Thesaurus and gazetteer protocols are emerging, with services such as ‘download all terms’, ‘query’ for matching terms, ‘get-broader’ and ‘get-narrower’ hierarchical searching. Doug then presented a possible KOS-based terminology server for the JISC Information Environment. In order to make full use of machine techniques, it is also necessary to rationalise indexing practices. Doug suggested that the KOS registry should include indexing praxis in an attempt to make indexing practice more explicit.
Conclusions
In her conclusion, Professor Carol Goble stated that, since the Grid is fundamentally metadata-driven, the digital library community is at its centre. There is no doubting the value of ontologies, but their development is expensive: we need both to invest in them and to curate them. There is a need for an internationally coordinated approach, in order to provide mappings between community ontologies. One solution which might provide rapid progress would be the ability of machines to build ontologies. Could the Grid deliver us schema and ontology services, rather than simply taking them from our communities? This may be the right moment to press for this, since the Grid architecture is being redefined in terms of services. Digital librarians are now required to codify the semantics of the digital order. The world of schemas and ontologies presents information science with perhaps its greatest challenge since the classification schemes and cataloguing standards developments of the 19th and 20th centuries.
I found this a fascinating meeting, in which two quite different communities, newly discovering common ground, strove to understand the differences between their views of the world, which emerged in several places. For example, both communities mean something quite different by the concept of an index. Another term which means different things within the distinct communities is ‘services’. These orthogonalities proved the need for the communities to remain in close dialogue with each other. The knowledge representation community also revealed that they had tools for building knowledge models which the digital library community would value, but do not normally see themselves as using. Does a key difference lie in the approach to building knowledge representations? Librarians generally adopt the schemes of forerunners (who are information scientists rather than librarians) and apply these, rather than build them anew. But in the digital world, they do not yet exist in many areas, so that those who describe and those who build must work in partnership. The question was raised whether ontology development can be mandated via grant conditions, in the same way as has been mooted for digital preservation metadata. Where communities are involved in building ontologies as teams, in a way analogous to the open source software movement, it is necessary to appoint ‘data curators’ to those teams. Ultimately there must be sharing (and librarians think naturally of sharing and reuse, as Rachel Heery had described), otherwise ontologies are likely to vie with each other for the same territory, and an inefficient ‘survival of the fittest’ process may result.
References
- National e-Science Centre http://www.nesc.ac.uk/
- Clinical e-Science Framework’ (CLEF) http://www.clinical-escience.org/
Author Details
John MacColl Email: John.MacColl@ed.ac.uk |
Article Title: “Metadata Wanted for the Evanescent Library”
Author: John MacColl
Publication Date: 30-July-2003
Publication: Ariadne Issue 36
Originating URL: http://www.ariadne.ac.uk/issue36/maccoll-rpt/