Hyper Clumps, Mini Clumps and National Catalogues: Resource Discovery for the 21st Century
Introduction
Keynote Speech: The Concept of a ‘National Catalogue’ - Jean Sykes
Interoperability: Architectures and Connections - John Gilby & Ashley Sanders
Making Sense of Hybrid Union Catalogues: Collection Landscaping in Complex Information Environments - Gordon Dunsire
Interoperability: The Performance of Institutional Catalogues - Fraser Nicolaides & George Macgregor
User Behaviour in Large-scale Resource Discovery Contexts - Dick Hartley
Futures and Plenary Question & Answer Session - Jean Sykes & Bob Sharpe
Conclusion
Introduction
The JISC-funded Copac/Clumps Continuing Cooperation (CC-interop) Project completed its work during 2004 and this event was planned to disseminate the key findings of the project. The day was chaired by Bob Sharpe, Director of ILS, University of Plymouth, Member of the JISC Integrated Information Environment Committee and Chair of the project Steering Group. Bob put the day in context by explaining that CC-interop had its background in the eLib Phase 3 Programme [1] and the Copac service [2]. The Large Scale Resource Discovery strand of eLib consisted of four distributed union catalogues or clumps, three of which were regional and have shown good sustainability by continuing beyond the project stage, now being live subscription-funded services. Copac gives free access to the online catalogues of major UK research libraries and is a JISC-funded service based at MIMAS.
At the end of the eLib programme, a gap was identified within the JISC development activities and the CC-interop partners were invited by the (then) JISC Committee for the Information Environment to submit a free-standing bid. This was successful and the project ran from May 2002 to April 2004. Project partners were the Centre for Digital Library Research (CDLR) based at Strathclyde and responsible for the CAIRNS Clump [3], the Copac Team based at MIMAS and the M25 Systems Team based at the LSE and responsible for the InforM25 service [4]. Staff with responsibilities for the RIDING service were initially partners also.
Bob noted that the project was not part of a specific JISC programme which was unusual, but filled an important niche.
The project was split into three work packages:
- A: looking at technical and semantic interoperability
- B: investigating collection description schemas
- C: analysing user behaviour in large scale resource discovery contexts
The aim of the conference was threefold:
- to allow the project staff to report their findings
- to consider resource discovery issues
- to share and openly discuss possible ways forward
Presentations
Keynote Speech: The Concept of a ‘National Catalogue’
Jean Sykes, Librarian and Director of Information Services at the LSE and Project Director, delivered the keynote speech on the ‘concept of a “national catalogue”’. She began her presentation with a reminder of the UK National Union Catalogue (UKNUC) Feasibility Study that took place in 2000-2001. Included in the ‘Final Report’ [5] were recommendations that a National Catalogue (as it is now referred to) should have its foundation in a physical union catalogue consisting of Copac (including the British Library) and additional important research collections. A further recommendation was that the architecture should be flexible to include distributed catalogues as technology improved and developed.
Jean indicated that a national serials catalogue was strongly recommended and this was now taking place with the Serials Union Catalogue (SUNCAT) Project [6] being developed by EDINA in partnership with Ex Libris and funded by JISC and RSLP (Research Support Libraries Programme).
Support for a National Catalogue of printed material was also indicated in the Research Support Libraries Group (RSLG) recommendations [7]. The final impetus for further research into the technology that might be utilised in the architecture for a National Catalogue came from a report looking back at the eLib Phase 3 Programme [8]. This recommended that ‘Further research and development work should be carried out on Z39.50’.
Jean summed up her presentation by stating that the overall aims of the project were to see how feasible it was to interlink distributed and physical catalogues, to identify technical and organisation issues to be addressed in a National Catalogue, and to inform the future development of such a service.
Interoperability: Architectures and Connections
Following a break, John Gilby, M25 Systems Team, LSE and Ashley Sanders, Copac Team, MIMAS, began the first of a series of four sessions looking at specific outcomes of the project. John began by reminding the audience of how the Z39.50 protocol operates using a client/server relationship and its popularity in the search and retrieval of bibliographic records.
This was followed by a brief overview of Copac and a typical distributed catalogue service, comparing and contrasting the differing technical architectures and amount of control over the searching process and subsequent results presentation to the user. Difficulties for both architectures can arise with the variable quality of institutional catalogue records, a theme that was mentioned throughout the day. John then introduced the concept of Z39.50 to Z39.50 middleware, probably best illustrated by a slide from his presentation:
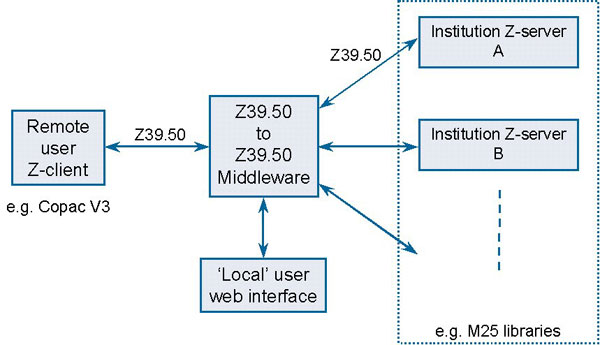
Figure 1: Z39.50 to Z39.50 Middleware
Z-Z middleware is a piece of software that ‘sits’ in the communication train between a Z-client and the distributed institutional Z-servers. It has to act as a Z-server (to what is referred to as the remote user Z-client) and as a Z-client (to the institutional Z-servers). It accepts and then distributes Z39.50 messages, forwarding user queries to the institutional Z-servers and then it needs to create an aggregated response from the Z-servers to send back to the user. CC-interop used the JAFER [9] software to implement Z-Z middleware for further testing and this was installed by the Copac Team at MIMAS. A copy of the Copac Z-client was set up as the user interface, and the middleware configured to connect to a number of M25 library Z-servers.
Ashley began his part of the presentation by successfully demonstrating a live search using the JAFER software, proving that the Z-Z middleware architecture does work and that distributed catalogues can be accessible to external users and services via Z39.50.
Library system Z-servers interpret incoming queries in different ways which can affect the search results. Middleware can be configured to transform the original query into a form more suitable for the individually connected Z-servers. This can increase the chance of a successful search but does remove an element of user control of the query. Z-Z middleware makes it easier to connect to multiple Z-servers, as the user only needs to know how to connect to the middleware. Staff supporting the middleware maintain the query transformations and individual Z-server connections, and would be well placed to solve any problems that arise.
Ashley then went on to describe the methods used to monitor Z39.50 response times using the JAFER middleware. An hourly Author search was carried out for a three-month period and the time for the institutional Z-servers to respond was logged. Responses varied broadly with library system type but over 90% of responses were received in under 2 seconds and some in under 0.125 seconds. It was noticeable that, generally, slower responses occurred overnight and that some of the fastest were during the late morning/afternoon period when institutional OPACs experience heavy usage.
Ashley concluded by reminding the audience that Z-Z middleware was a potential architecture for the distributed elements of a National Catalogue, enabling clumps to be ‘plugged into’ an information environment. There is interest from the eLib clump services (and others) in the potential implementation of JAFER for their services which would go some way to building part of the JISC Information Environment or National Catalogue.
Making Sense of Hybrid Union Catalogues: Collection Landscaping in Complex Information Environments
Gordon Dunsire, Depute Director, CDLR, Strathclyde, described how metadata for the same copy of an item might be offered within multiple catalogues in the same information environment; for example, a record might appear in Copac, in a clump and also be harvested in one or more catalogues, and complexity arises due to this duplication, leading to confusing and inefficient results for the user. The JISC functional model of the Information Environment advocates the use of Collection Level Description (CLD) to create user-defined ‘landscapes’ for resource discovery. For CC-interop, the Scottish Collections Network (SCONE) [10] was used as a test-bed to investigate some of the issues involved in landscaping an environment of hybrid union catalogues. SCONE was found to be a suitable test-bed, as close scrutiny of SCONE and other popular CLD schemas in use in the UK, including RSLP and DC, showed a high degree of compatibility. CLDs were also examined to see if it was possible to map or describe Copac, InforM25 and RIDING metadata with the SCONE schema.
The concept of ‘functional granularity’ (the level of aggregation described in CLDs deemed useful for resource discovery or collection management) was found to be a key tool allowing a collection to be defined on the basis of its metadata aggregations. CLDs based on union catalogues can be related hierarchically to existing CLDs based on contributors’ own (local) collections. Thus the ‘landscape’ can be simplified by only including the ‘closest’ most appropriate metadata aggregation matching the user’s definition. This requires the metadata aggregators to contribute union catalogue information to CLD services, and the services themselves to ensure collection hierarchies are maintained. Gordon concluded that further research could be undertaken in defining metadata aggregation parameters and in developing tools for more flexible landscaping of differing information environments.
Interoperability: The Performance of Institutional Catalogues
Another ‘double act’, Fraser Nicolaides, M25 Systems Team, LSE and George Macgregor, Researcher, CDLR, Strathclyde, looked in more detail of what was going on in libraries, in particular with cataloguing practices and Z-server behaviour. Fraser began by reporting on the outcomes of a study that looked at the relative performance of institutional Z-servers and Copac, focussing on non-system architecture issues (semantic interoperability).
Searches were conducted against Copac and six CURL libraries using Z39.50. Four consistent differences in performance were identified:
- the currency of data within a physical union catalogue
- the availability of records that describe electronic resources
- the definition and processing of searches
- the cataloguing and indexing policies and practices at the individual institution
The latter two differences merited further consideration.
There still exist considerable variations between all of the systems tested in their support for Bib-1 attributes [11] to the extent that there was difficulty in finding attribute combinations that were shared by all of the tested systems. Exacerbating these difficulties was Z-server default behaviour where query attributes were ignored or replaced due to their being unsupported. The solution to these difficulties is the vendor support of a common suite of Bib-1 attribute combinations such as the Bath Profile [12]. There is a noticeable vendor reluctance to support Bath for a variety of reasons and also customer ignorance of the profile and the areas and levels of the profile relevant to them.
Fraser concluded his part of the session by talking about the bibliographical completeness of catalogue records and the indexing policies that effectively determine how those records are accessed. Physical union catalogues, such as Copac, have a distinct advantage over distributed systems in that records can be cumulatively enriched by records from the contributing institutions. Institutional indexing policies determine which record fields are indexed and to which (Z39.50) access points or Bib-1 Use attributes these indexes are mapped. Libraries which wish to participate effectively in distributed catalogues must detail to their system vendor the measure of semantic interoperability they require for their Z-server. Variations in cataloguing and indexing policies are often the product of historical and local requirements and it is arguable whether these policies should, or indeed, could be challenged.
George raised the question of what could be done to improve system interoperability through coordination of cataloguing and indexing policies. As part of the eLib-funded CAIRNS Project, a Catalogue Issues Working Group was set up and this body continues to meet regularly. The key output from the group was a set of guidelines for cataloguing and indexing in Scotland. These have been successful with a number of institutions changing their policies and practices to fit better with non-local information environments.
CC-interop sought to build on the CAIRNS guidelines and to that end, held workshops that were attended by SCURL, CURL, M25 and Scottish FE cataloguers. At the workshops there was a strong consensus that prescriptive guidelines were essential to assist with interoperability and that libraries need to ‘Think Globally, Act Locally’. One recommendation was that the Bath Profile should be developed to encompass the scope and content of specified indexes, for example to enable standard mappings from MARC21 fields to Z39.50 access points. It was also proposed to produce guidelines on required Bath conformance for any given service, on the premise that reducing choice in consortia would benefit interoperability.
User Behaviour in Large-scale Resource Discovery Contexts
Dick Hartley, Head of Information and Communications, Manchester Metropolitan University and representing the Centre for Research in Library and Information Management (CERLIM) began the final project outcomes presentation by giving full credit to his colleague, Helen Booth (CERLIM) who had carried out a lot of the tasks involved in data gathering, analysis and reporting. CERLIM was sub-contracted by the CC-interop Project to study user behaviour in searching both physical and distributed union catalogues. The full report [13] is available on the project Web site and contains full details of the methodology used for data gathering and analysis.
Some of the key findings noted in Dick’s presentation are detailed below.
- Searchers use a wide range of search criteria
- The term ‘union catalogue’ was mostly unknown - system providers take terminology for granted and there was confusion with terminology used on the services
- Performance and ease of mastering the services is gauged by other Web tools, typically Google but also Amazon
- Duplicate records within results are not liked and most searchers are unwilling to plough through large result sets. (Arguably the opposite can be true with Google where searchers seem less concerned about duplicates and large result sets)
- Many expected a fast response time and some abandoned searches as they were perceived as slow
- Librarians were well aware of different union catalogues but had reservations with both architectures
- Librarians felt that Serials union catalogues are the most important and after this, rare books and regional catalogues.
There is clearly a demand for union catalogues (as Copac usage data shows) and this demand could be higher if there was greater awareness of the existence of the services. The design of these services needs to take into account the user expectations, such as simple interface, speedy response and not losing the user. Comments indicate that the current investment in SUNCAT appears to be the correct decision.
Futures and Plenary Question & Answer Session
Jean Sykes and Bob Sharpe each gave short presentations to start off the final session of the day. Jean commented that the project was the only known investigation of interoperability between physical and distributed union catalogues and that as far as the partners were aware, the first project to investigate user behaviour (when searching union catalogues) through observation. Jean then summarised the various outcomes of the project and suggested areas where further research could take place.
Bob began by looking at what were the big issues from the project. He suggested that semantic interoperability and user behaviour in federated searching are issues that should be taken further. Technical interoperability, not only with Z39.50 but with Search/Retrieve Web Service (SRW) also, needs to move forward. He related the outcomes of the CC-interop Project to the work he had been involved with in the JISC Development Strategy Working Group. He showed slides of what a user’s resource discovery world might look like in 2014, suggesting intelligent agents that learn about a user’s world and inform the user of new resources as they appear would be commonplace. These agents form part of the technical vision with a user having myGoogle (possibly an academic or a local community Google), myBlog, myIP, myCredit, myCommunities, myID, MyProfile and myResources. A key element in this is the myCommunities in which a user forms different relationships depending on which community it is. Work has begun in looking at how the ‘Google approach’ can benefit these different communities.
Bob reiterated the view that user behaviour in federated searching is a big area to pursue. Semantic interoperability is important, not only in the ways referred to during the day, but also in others such as where words mean different things in different disciplines. Searching and knowledge extraction is also an important area as is technical interoperability, especially when looking to the future and taking into account Web services and related developments.
What has happened with the CC-interop project outcomes? A report from the project went to the JISC Integrated Information Environment Committee in June 2004 where it was agreed that there needs to be a wider focus for resource discovery. During July 2004 a case was made to the JISC sub-committee chairs for a resource discovery landscaping study, as issues raised were relevant to several of the JISC committees. Bob suggested that resource discovery warranted its own programme of work within JISC as it is an important area and he drew a parallel to the ‘gap’ identified when the CC-interop Project came about. UKOLN has been tasked with the landscaping study which potentially has a large remit and will need to be kept manageable. The study is planned to be ready in January 2005 and might lead to a new programme of work during 2005.
Bob then moved on to the plenary open question and answer session. The first area of discussion was that the systems tend to be thought about in terms of today’s users. Perhaps there is benefit in looking at how children carry out searches as there are differences in the way they find information (e.g. often browsing more) and they are the users of the future. Studying children’s searching behaviour at an early age and then looking at the same group again a few years later could reveal how their methods have changed.
There was an extended discussion about possible trends in the future searching strategies and, not surprisingly, Google was mentioned a number of times. There is the Google Desktop Search (which searches files, emails, etc) and the tie-up with searching WorldCat which shows that the nature of searching is changing. Google are known to be talking to libraries and similar organisations about deep-level searching. The integration of the ‘Google approach’ and the more traditional structured information approach is being tested. Searching nowadays can be extremely complicated with users being in local or global communities (sometimes both at the same time).
Sustainability at a practical level of the different architectures presented during the day was considered. It was put forward that distributed catalogues were relatively low cost to maintain and that, as was shown by services such as CAIRNS and InforM25, their main user communities contribute or fully meet the costs involved.
The final area of discussion considered issues around searching for material such as video and images, by visual means rather than by textual metadata. CC-interop perforce had been investigating searching issues after the metadata had been created but the issue was interesting. Images could be scanned for a particular shape or colour, the results from which become the metadata aggregation that is relevant in the distributed catalogue scenario. Much useful work has been done on image retrieval but there exists a huge gap in what can be achieved and what is needed.
Conclusion
The event proved that resource discovery is an important area for continued research. CC-interop has looked at specific interoperability issues, has found some solutions but also raised more questions. The trend to relate every search to Google is increasing and it will be interesting to see how this trend continues. Z39.50 is maturing and unlikely to be replaced in the short to medium term. The distributed catalogue services are well established and can work alongside, and interoperate with, large physical union catalogues. The feedback from delegates was very positive proving that the library community continue to regard resource discovery issues as highly relevant.
All presentations are available on the CC-interop Project Web site [14].
References
- The Electronic Libraries Programme Web site http://www.ukoln.ac.uk/services/elib/
- Copac home page http://www.copac.ac.uk/
- Co-operative Information Retrieval Network for Scotland (CAIRNS) http://cairns.lib.strath.ac.uk/
- M25 Consortium of Academic Libraries InforM25 service http://www.m25lib.ac.uk/
- Stubley, P, Bull, R, Kidd, A, “Feasibility Study for a National Union Catalogue: Final Report”, 25 April 2001 http://www.uknuc.shef.ac.uk/NUCrep.pdf
- SUNCAT Project Web site http://www.suncat.ac.uk/
- Research Support Libraries Group Final Report, 2003 http://www.rslg.ac.uk/final/final.pdf
- Pinfield, S, ‘Beyond eLib: Lessons from Phase 3 of the Electronic Libraries Programme’ 23 January 2001 http://www.ukoln.ac.uk/services/elib/papers/other/pinfield-elib/elibreport.html
- Java Access For Electronic Resources (JAFER) Toolkit Project, JISC 5⁄99 http://www.jafer.org/
- Scottish Collections Network (SCONE) http://scone.strath.ac.uk/service/
- Attribute Set Bib-1 (Z39.50-1995): Semantics, ftp://ftp.loc.gov/pub/z3950/defs/bib1.txt
- The Bath Profile: An International Z39.50 Specification for Library Applications and Resource Discovery, Release 2.0, 2004, http://www.collectionscanada.ca/bath/tp-bath2-e.htm
- Booth, H, Hartley, R J, “User behaviour in the searching of union catalogues: an investigation for Work Package C of CC-interop”, CERLIM, February 2004, http://ccinterop.cdlr.strath.ac.uk/documents/finalreportWPC.pdf
- CC-interop Project Web site http://ccinterop.cdlr.strath.ac.uk/hyperclumps.htm