Looking for a Google Box?
Most Web sites of any size want to offer a facility to perform a free-text search of their content. While we all at least claim to believe in the possibilities of the semantic web, and take care over our navigation aids and sitemaps, we know that sooner or later our readers want to type 'hedgehog' into a search box. Yes, even http://www.microsoft.com [1] returns plenty of hits if you try this. So how do we provide a search, in the cash-strapped Higher Education world of large, varied and unpredictable Web site setups, often containing a suite of separate servers? Brian Kelly's surveys (reported for example in Ariadne 36 [2]) have shown that there is no obvious solution. There are, perhaps, four directions we can take:
- Evaluate the complete range of closed and open source offerings, pick the best, and be prepared to pay a yearly licence fee of an unknown amount
- Develop our own private search engine, possibly based on ht://Dig [3] or egothor [4] code
- Make use of the free Google index of our pages
- License Google technology to do local indexing
Each route has its attractions, but the latter two are particularly attractive because of the high degree of trust in, and familiarity with, Google. But the public search has problems:
- Google cannot see inside our protected sites
- Every search transaction has to leave our site, is dependent on international networks, and uses up bandwidth
- The depth and frequency of search is not guaranteed
- Google may withdraw the service at any time
So can we consider our own private Google? At Oxford, we had a Google Search Appliance (GSA) on free trial over the summer, and this article describes our experiences.
A Google Search Appliance is a self-contained sealed computer which is installed within your network; it both indexes Web sites and delivers search results in the familiar Google way. The indexing is neither affected by, nor influences 'Big Brother' Googles, and the box does not need to communicate at all with the outside world.
Installation and Maintenance
The smart bright yellow box was delivered ready to fit in a standard rack mount. After some swearing and pushing, it was fitted in next to some mail servers in about half an hour. We plugged in a monitor and watched it boot up successfully. A laptop connected directly was then used to do the initial configuration, set up an admin password and so on. Playing around with IP numbers and so on took another hour or two, but we fairly soon arrived at a running Google box, administered via a Web interface, and we did not go back to the hardware while we had the machine. Each day it sent an email report saying that it was alive and well, and a system software update was easily and successfully managed after a couple of months.
We contacted Google support by email 3 or 4 times with non-urgent queries about setup, and they responded within a day giving sensible answers. Their online forum for GSA owners is quite good. We did not have occasion to request hardware support.
Configuration
All the configuration work is done via simple Web forms. Not surprisingly, however, it takes a fair amount of time and experimentation to get straight. After some initial experiments on the local site only, and making the mistake of putting the box on our internal departmental network, we switched it to being simply an ox.ac.uk machine, so that it had no departmental privileges.
The system works by having initial seed points, and then a list of sites to include when crawling. Our seed list was simply http://www.ox.ac.uk/-any site not findable from here would not be visited. The inclusion list was created by getting the registered Web server for each department or college, and then adding other machines as requested.
The second part of the configuration is the list of document types to exclude. We set it to index Word and PDF files, but exclude
- Microsoft Excel, Powerpoint, Access and RTF
- graphics files, fonts, multimedia, etc
- executables
- a set of url patterns which foul up locally on experience, either because they are duplicate forms of Web pages, or go into endless loops retrieving from databases.
Some examples, which used extended regular expressions, from our configuration were:
- contains:PHPSESSID
- contains:logon.asp?
- contains:/homepage/searchresults
- contains:&&normal_view=
- contains:timetableweek.asp
- users.ox.ac.uk/cgi-bin/safeperl/
- www.seh.ox.ac.uk/index.cfm?do=events&date=
It is likely that this list would settle down over time as Webmasters learned to understand what the box was doing.
Serving Documents, and Crawling
After the configuration described in the previous section, our system settled down to indexing about 547,000 documents. The admin screens say it had an index of 33.23 GBytes. How much this would rise to if all Webmasters adjusted their content seriously, and as more facilities came on line, is hard to say, but it seems reasonable to suggest that a capacity of between 500,000 and 750,000 documents would provide a useful service.
The GSA indexes continuously, hitting servers as hard as you let it, and has a scheme to determine how often to revisit pages; generally speaking, it seldom lags more than a few hours behind page changes; it is possible to push pages immediately into the indexing queue by hand, and remove them from the index by hand. Most Web pages at Oxford seem to be pretty static, judging by the rather low rate crawl after a few weeks of operation.
Changes to the setup take a while to work their way through the system (about 24 hours to get to a clean state after removing a site), but individual sites can be blocked at any time from the search, or individual pages refreshed instantly.
We did not make much adjustment for individual hosts. The default is to not make more than 5 concurrent connections to a given Web server, but for 5 of our servers this was reduced to 1 concurrent session after complaints from Webmasters.
Collections and Search Forms
At the heart of the Googlebox setup are collections. These are specifications of subsets of the index, allowing departments and colleges to have their own search. The configuration for a collection has URL patterns to include, and patterns to exclude. Setting up an individual Web site to have its own search form accessing the GSA is easy. Here is the one for our Computing Services Web servers:
<form method="GET" action="http://googlebox.ox.ac.uk/search">
<span class="find">
<label for="input-search">Find </label>
</span><br/>
<input type="text" name="q" id="input-search" size="15"
maxlength="255" value="Enter text"/>
<br/>
<span class="find"><label for="select-search">In </label></span>
<br/>
<input type="radio" name="site" value="default_collection" />Oxford
<br/>
<input type="radio" name="site" value="OUCS" checked="checked" />OUCS
<input type="hidden" name="client" value="default_frontend"/>
<input type="hidden" name="proxystylesheet" value="default_frontend"/>
<input type="hidden" name="output" value="xml_no_dtd"/>
<input type="submit" name="btnG" value="Go"/>
</form>
which produces:
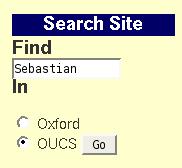
Figure 1: Example Search Form
The key parameters here are site, which determines the collection to be searched, and proxy stylesheet which determines how the results will be rendered. The results from the Googlebox come in XML, which can be processed by your own application, but are normally filtered through an XSLT transform. This is fairly easy to understand and modify, either with direct editing or with Web forms.
The different front ends can be customised in a variety of ways. One is to force a priority result for a given search term. For example, we set this for keywords 'open source' and 'webmail', so any use of those words forced chosen sites to the top.
Collections can be administered on the GSA admin pages by non-privileged users who can also see search logs and analyses.
Problems
During our trial we had a meeting with representatives from Google and discussed the main difficulties which had arisen during the trial. These were:
- We had identified oddities in searching (a search for Pension did not produce the expected pages in the rankings), but we did not find a clean explanation. Subsequently, the software update and consequent complete re-indexing seemed to solve the problem.
- The Oxford setup would require individualised configuration for several hundred separate units (which would be delegated to unit Webmasters). This is done on the GSA via a Web form, and cannot be created externally and then uploaded; configuration by 'super unit' (ie all science departments) is not directly supported. This poses a definite maintenance issue for a complex site, and we would expect it to be changed in a future software release. The Google representatives understood the issue, but could not offer an immediate solution.
- The price of the box is not trivial; you have to decide how big a box you need, as the configuration has limits on how many documents it will index. For a point of comparison, we decided that Oxford would need a capacity of between 0.5 and 0.75 million documents. Some setups may need the optional security module, which is an extra cost.
- The GSA naturally lives inside the firewall, and so has access to sites which are restricted to the internal network. You cannot therefore simply allow the search interface to be seen outside the site as it would show external users about restricted information (and, via the cache, probably display them). Therefore we needed a view of the index which takes the restrictions into account. The Google technical representatives, both at the meeting and in subsequent email discussion, suggested various schemes, none of which we were able to implement. The simplest suggestion was to buy two boxes, one for outside the firewall and one for inside. The most likely involved routing all searches through a proxy server maintained separately, which would check all accesses to see if they would work from outside the firewall, and annotating the database according. It is worth noting that if all Oxford Web sites had put their restricted material on a separate Web server (eg oucs-oxford.ox.ac.uk) or used a naming convention (eg oucs.ox.ac.uk/oxonly/), it would be easy to configure the box to provide the external search as needed.
Some of these problems would likely arise at other similar sites.
Conclusions
It is straightforward to describe the Google Search Appliance:
- It performs as specified, is easy to use, and has powerful configuration and maintenance options. It provides an effective Web index.
- It costs real money (a per-two-year fixed fee), and is dependent on the vendor for support in the case of hardware or software failure.
- It is not maintenance-free-Oxford, for example, would expect to continue to devote ongoing time to tuning and analysis (perhaps 0.05 FTE).
- It is not clear that a single box can always provide an external search as well as an internal one.
Whether the GSA is the right solution depends on a number of factors; plainly, one is money, but that depends on the relative importance we all attach to our searching. More important is the setup in which a GSA would be placed, and what it would be expected to do. To provide an intranet index of a single server, it will provide an instant working system. If there is no restricted content, or the restricted content is all on one server, it is easy to use the box to provide external and internal searching. If, however, you have private pages scattered everywhere, using IP ranges to restrict access, the GSA is not necessarily an ideal system.
We decided in the end not to go with the GSA at Oxford, but it would be quite surprising not to see some of the nice yellow boxes emerging in the UK educational community soon.
I would like to thank Google for their patience and helpfulness during our trial. They asked me not to put any screen dumps in this article, or quote prices, but have otherwise encouraged me to discuss our experiences.
References
- Microsoft http://www.microsoft.com
- WebWatch: An Update of a Survey of Search Engines Used in UK University Web Sites, Brian Kelly, July 2003, Ariadne 36 http://www.ariadne.ac.uk/issue36/web-watch/
- ht://Dig. ht://Dig. http://htdig.sf.net/
- egothor. http://www.egothor.org/