Opening Up OpenURLs with Autodiscovery
Library users have never before had so many options for finding, collecting and sharing information. Many users abandon old information management tools whenever new tools are easier, faster, more comprehensive, more intuitive, or simply 'cooler.' Many successful new tools adhere to a principle of simplicity - HTML made it simple for anyone to publish on the Web; XML made it simple for anyone to exchange more strictly defined data; and RSS made it simple to extract and repurpose information from any kind of published resource [1]. Recent efforts within the digital library community (OAI-PMH [2], SRW/U [3] and METS/MODS/MADS [4] [5] [6]) similarly lower the technological costs of implementing robust information sharing, search and description.
A wide gap remains, however, between 'cool' new applications (photo sharing, link logging and weblogging) and library services. On one hand, by observing Web sites like Blogdex and Technorati, we can see how tools like RSS make it easier for anyone to build layer upon layer of new services on top of one base technology. On the other hand, there are fewer examples of our nascent library-borne tools and standards being extended outside the relatively narrow sphere of library-specific applications and services.
In this article, we focus on one opportunity to bridge this gap by promoting the broader application of OpenURL-based metadata sharing. We show how simple designs operating separately on the two components of OpenURLs can not only solve the appropriate copy problem, but also foster the sharing of references between a much broader variety of applications and users. We claim that doing so will promote innovation by making the OpenURL model more accessible to anyone wanting to layer services on top of it. This, we argue, will lead to the wider adoption of the standard to share references in both scholarly and non-scholarly environments, and broader use of our library-provided resources.
The NISO AX specifications for OpenURLs provide a framework to solve the 'appropriate copy/service' problem [7] [8]. An OpenURL consists of two logically distinct components [9][10]:
- the address of an OpenURL resolver and
- bibliographic metadata which describes the referent article.
When users visit OpenURL links with both components, the resolver presents a list of local services (e.g. a link to a locally subscribed full-text copy, a citation report, an interlibrary loan request) for that referent. Note that the first component (the resolver address) is institution-dependent , and the second component (metadata) is institution-independent. Most current OpenURL-implementing services automatically bind these two parts together based on users' incoming network addresses. In practice, this implementation pattern only scratches the surface of what the OpenURL model makes possible. As originally conceived, and as the standard is written, the two OpenURL components can easily be separated, reconfigured, and reattached as required by distinct information sharing applications.
We can imagine a variety of applications for more adaptable OpenURLs that would allow users and applications to make more choices about when to resolve OpenURLs:
- when to redirect them from one resolver to another
- when to store their bibliographic metadata components for later reuse and
- when to exchange bibliographic metadata between non-resolver applications
Indeed, the broader need to share links to information resources has led to a variety of approaches already implemented without the OpenURL standard. One widely seen pattern is a weblog 'What I'm Reading' section; these typically present readers with useful bibliographic metadata and a link to a record for that item in an online vendor catalogue. That so many weblog authors use this pattern indicates that demand for simple ways to connect authors and readers to bibliographic metadata (and, implicitly, convenient ways to obtain described items) is much greater than the demand solely for links to full text versions of scholarly journal articles. In an earlier article [11], the authors argued that:
' ...we can consider the functional areas of linking, reference management, and weblogging to be service points on a single continuum of information gathering, study, and creation. Following a reference from a weblog or from a scholarly article are each similar steps in exploring threads of related ideas. Capturing a reference in your own weblog or reference library indicates that the citation somehow relates to your own thought process. Publicly citing a reference more closely associates your thinking with that of others.'
It is so common for webloggers to read widely and to cite and comment upon other weblogs that the authors of weblog publishing systems make the process of citing an external Web site as quick and automated as possible. Consider the approach taken by the Wordpress weblog system:
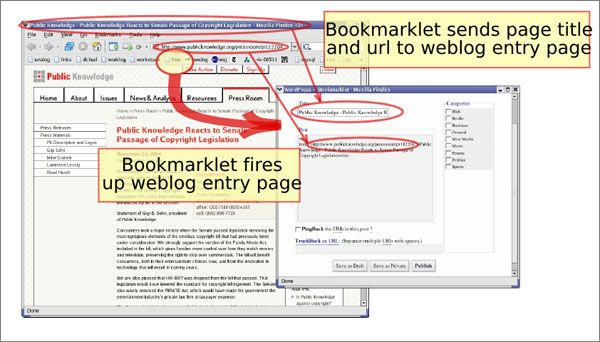
Figure 1: Screenshot of 'Blog This' Bookmarklet
In Figure 1 we see that a user can click on a special 'Blog This' bookmarklet (a Web browser bookmark containing JavaScript to perform a particular operation) to send the title, URL, and optionally selected text from a page they wish to reference to a weblog. The captured URL is an ordinary URL (not an OpenURL), and the captured title is whatever the page author placed into the HTML <TITLE> tag. While it is also possible for webloggers to create such references manually, this simple technology allows them to make citations more quickly and more accurately by reducing the risk of copy-and-paste errors.
Now consider an academic example where a researcher finds an article to read via Pubmed. In Figure 2 we see the familiar OpenURL two-step: from a reference at Pubmed (at top left), to a direct full-text link (at bottom). Additionally, if a user enters Pubmed through a specially crafted URL available on a medical library Web site, they might also be able to follow that reference to their institutional OpenURL resolver (at right).
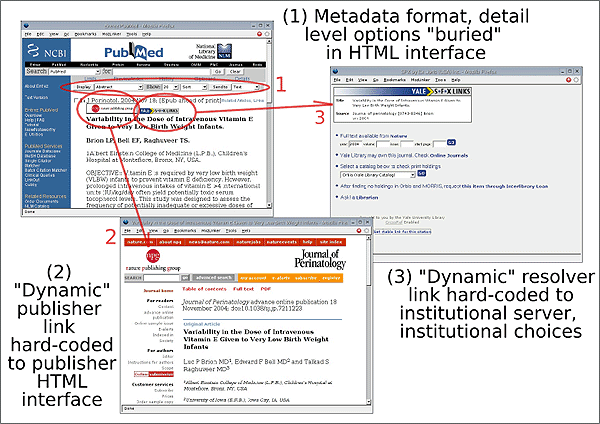
Figure 2: Irreversible OpenURLs in Best-of-Breed Environment
In Figure 2, the researcher might want to click that same 'Blog This' bookmarklet at any of the three screens, hoping to capture the article title, the link to the clicked-after page, and (ideally) additional metadata about the article such as authors, volume, issue, pages, and source. We can see, however, that the same 'Blog This' bookmarklet, trained only to capture a URL and <TITLE>, would not provide the researcher with useful information. In each screenshot, the URL displayed on the browser's location bar is a publisher-specific version, which is, in many cases, not a stable URL which can be cited. It may contain session information, which will expire in the future; it might contain Web application parameters that are later changed by the publisher; it might even simply point to a server that is later replaced or moved. Moreover, the contents of the HTML <TITLE> field do not necessarily correspond to the title of the article. In many cases we may only have a generic title ('Full text') or simply the name of the vendor ('SFX At Yale') or database publisher ('Entrez Pubmed').
A better choice of 'what to Blog' would be the OpenURL passed between pairs of services in Figure 2. The OpenURL would contain the necessary metadata, or an identifier resolvable to the necessary metadata, for researchers to capture the citation itself for immediate republication into a weblog. Few researchers, however, would be likely to take the trouble to capture the OpenURL from the clickstream between applications, and to paste the OpenURL by hand into their weblogs. And most weblog engines have yet to accommodate the OpenURL model by helping to simplify this process the way bookmarklets currently simplify the process of posting comments about other sites. Even if this process could be simplified (some resolver products, for instance, provide an easy way to capture such a 'stable link'), their weblog readers would not be able to reach services presented by researchers' own institutional OpenURL resolver (pointed to in the captured OpenURL) if they were not members of the same institutional community. Even more frustratingly, many high-end resources like Pubmed and full-text database themselves provide alternate application interfaces to their metadata and search functions, but tool providers cannot simply 'scrape' that knowledge without coding resource-specific (and, therefore, expensive to maintain) rules into Web browsers or other tools.
What weblog authors should be able to do is to get all of the OpenURL metadata back into their weblog with that one 'Blog This' click, instead of just a random HTML 'title' and an arbitrary remote-application-defined URL. We can see, however, that the transient model of currently-implemented OpenURL service connectivity makes it difficult for individuals to pass OpenURLs further along to additional applications of their choosing. And, even if aspects of these tasks are made simpler, the OpenURLs they do share remain limited in usefulness.
Several initiatives demonstrate promise towards solving these problems. The OpenURL Router [12] serves hundreds of European institutions with a resolver-bounce model. This lets publishers use a single base domain in their OpenURLs, obviating the need to maintain institution-specific network information. This solution is only in place in one part of the world, however, and because it remains closed to outside resolvers, it does not yet speak to how, say, small UK publishers might let readers from other regions bounce to their own resolvers. That being the case, we can imagine that linking such routers across regions might help. OCLC has been developing a resolver registry that perhaps might support such inter-regional router linking, but it has not yet been publicly released. Separately, a more general model of service registries is being developed in the UK by the IESR [13] [14] initiative and the NSF-funded OCKHAM Project [15] in the US. Both of these efforts, overlapping in scope and working together, offer much promise, but are still under development and therefore are not yet in widespread use.
At the same time, our community has recognised that computer users want to simplify how they collect and share information. The 'Gather, Create, Share' motto evident in the Flecker/McLean Report [16] from the DLF (Digital Library Foundation), which describes interoperability issues in digital library services, personal collection tools, course management systems, and online portfolios, articulates this model of user demand succinctly. Specifications from IMS [17] and collections of common information-sharing use cases gathered by participants in the Sakai Project [18], among other efforts, further document and clarify the need to deliver scholarly and learning management services that plug in to this mentality.
Problem Statement
To meet this demand, any information-rich resource anyone provides anywhere would be made to work, in part, like this:
- User sees something they wish to capture/cite/copy/share/get services for, so
- User clicks one button, and
- The desired object moves, magically, to wherever it is told to go, along with its metadata (or just its metadata, depending)...
- ...Even if that is a different place (or places) from one time to the next.
Fortunately, wherever bibliographic information needs to be exchanged between applications, users, or diverse services, the OpenURL specification already provides a robust framework for doing so. Its model is easy-to-implement and vendor-, platform- and genre-neutral. A variety of developers and users outside our comparatively small academic library community are already stitching new information-sharing applications together faster than we can collect use cases, but without benefiting from the simplicity of OpenURLs. In the short term, it might benefit all to find simpler ways to interject our OpenURL resolvers - among other services -- into the broader world of personal library development.
Demonstration: Simple OpenURL Autodiscovery
This might seem like a lot to ask for, but examples of such simplicity at work already abound. Take, for instance, RSS Autodiscovery [19]. By embedding a simple metadata element (a <LINK> tag) in the HTML header element of a weblog or other site template, Web publishers can simply advertise the availability of one or more RSS feeds for their site. Because the manner in which this tag is used is simple and well-known, Web browser developers have seen fit to include support for automatically discovering, or 'autodiscovering,' RSS feeds, and making it easy for users to subscribe quickly to autodiscovered RSS feeds within the browser's core interface with a special icon.
Thus, by embedding a pointer to a site's RSS feed on every page of a site, and by ensuring that pointer matches an agreed-upon pattern, users and their software tools can be made to find RSS feeds automatically. The agreed link syntax is itself very simple:
<link rel="alternate" type="application/rss+xml" title="RSS" href="http://example.net/rss" />
What if OpenURLs could also be autodiscovered? The authors have experimented with this in several applications, and the results are promising. Aiming for simplicity for users and implementers alike, we have cast OpenURLs on several of our own sites' pages with a few simple additions that enable similar functionality.
For our prototypes, we changed services we operate to generate 'bare' OpenURLs using the HTML "name" element, and we also added two simple attributes: 'title' and 'rel':
<a name='issn=0367-326X&volume=75&issue=7-8&spage=782' rel='alternate' title='OpenURL'>
The "name" attribute is intended to identify a single, specific location within an HTML document, and is useful here because "name" anchors are typically not visible. This allowed us to experiment with inserting discoverable links into existing services without disturbing unsuspecting users. Note that while using both the "title" and "rel" attributes in this manner are technically valid according to the HTML specifications, use of the "name", "title", and "rel" attributes on the "a" element in this exact way is an experiment [20]. The authors readily admit that this combination feels like a bit of a 'quick hack.' That said, annotating bare OpenURLs in this manner made it simple for all of us quickly to meet our prototyping objective of 'making quick hacks easy.' Also, because the "title" and "rel" attributes are both components of the RSS autodiscovery pattern used for "link" elements, this approach seemed to be a reasonable starting point for discussion. This general approach, of JavaScript code operating dynamically to change OpenURLs as befits distinct users, is not itself original, either [9][10]. Our approach simplifies previously described techniques in that client applications only operate on user preferences (for a particular resolver) rather than the exchange of cookies across applications. We hope this simpler model might expand the variety of application types and publishers that leverage these well established, but under-utilised, ideas.
After adding this new OpenURL pattern to our services, we focused on adding OpenURL autodiscovery support to client applications, starting with Web browsers. This required two steps: first, because we needed a list of resolvers to demonstrate the feasibility of dynamically assigning appropriate resolver links to meet users' institutional affiliations, we invited colleagues subscribed to a library mailing list to share basic information about their local resolvers for experimental purposes. This yielded for use a list of a dozen resolvers from institutions in five different countries, including resolver service names, locations, 'catch phrases' and link button images. Next, we generated a set of JavaScript bookmarklets that would allow users from any of those dozen institutions to rewrite OpenURLs that match the autodiscovery pattern specified above [21].
There follow several examples of prototype OpenURL autodiscovery in action in systems developed independently by the authors. Figure 3 shows CiteULike, a research article 'linklogging' system [22].
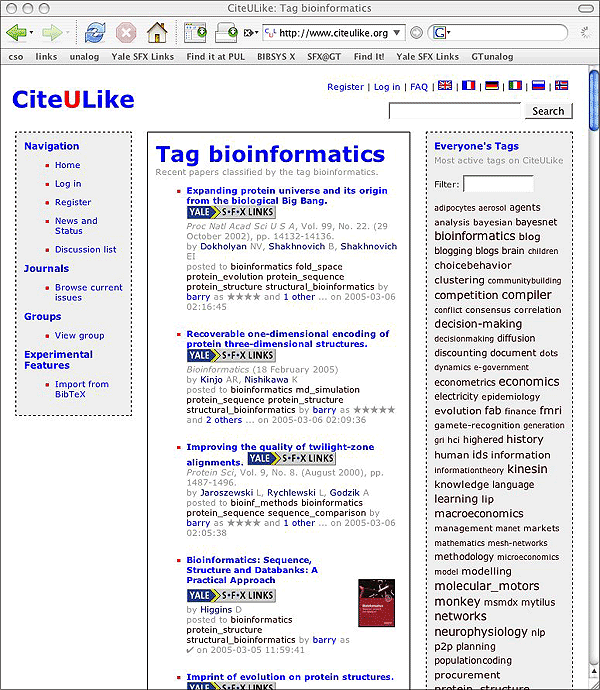
Figure 3: OpenURL Autodiscovery in CiteULike
Figure 4 shows the Canary Database, an interdisciplinary resource [23].
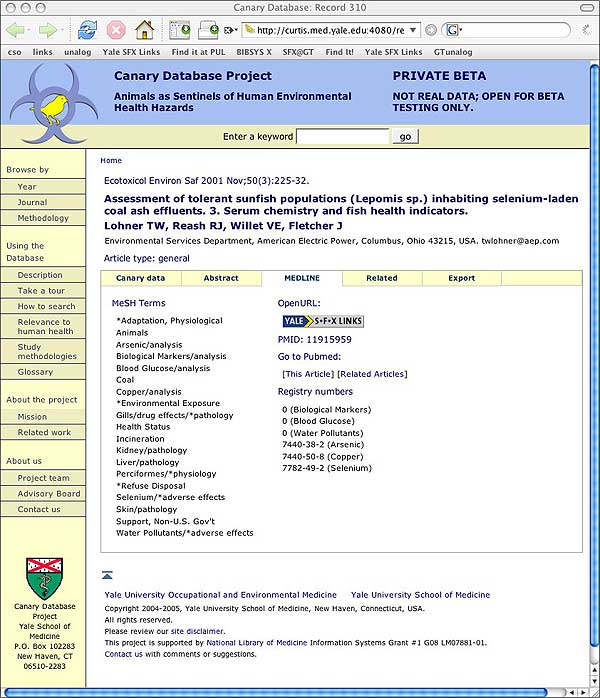
Figure 4: OpenURL Autodiscovery in the Canary Database
Neither author's service maintains a list of institutional resolvers, or network address ranges, or even user-specified resolver preferences, but in both figures, user-appropriate OpenURL buttons appear next to citations. For both CiteULike and the Canary Database, the authors needed only to change their sites' respective HTML templates slightly. Only the autodiscoverable OpenURLs, with the "rel" and "title" attributes as described above, were added, with no special additional knowledge of their users.
Demonstration: Generic OpenURLs in Weblogs
Both of these are custom-built applications for scholarly researchers. To demonstrate autodiscoverable OpenURLs in a broader context - weblogs - we wrote plug-ins designed to work with the popular Wordpress and PyBlosxom weblog toolkits. Once a weblog plugin is installed (quickly, as each is only a few lines of code), a weblog author can then add a Wordpress "custom field" called "openurl" to any entry, with a value of the OpenURL query string, or a line in any PyBlosxom entry that looks like this to any entry:
"openurl::Lucene in Action (book)::title=Lucene in action&isbn=1932392481"
With these simple extra actions taken by weblog authors, users with the JavaScript "appropriate resolver" piece installed in their Web browser will then see the resolver buttons pop up in the browser window, as depicted in Figure 5.
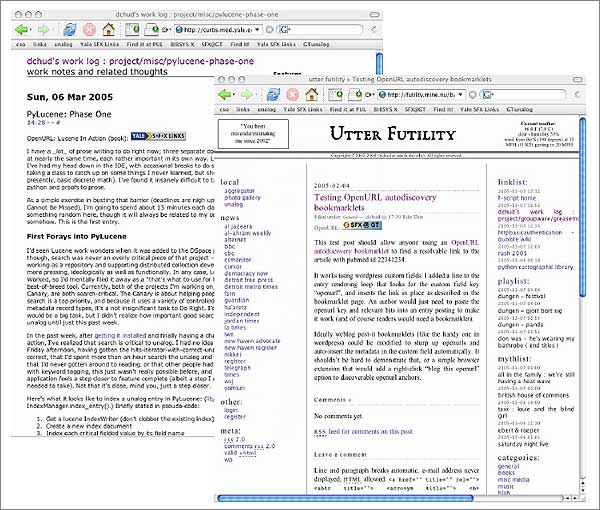
Figure 5: OpenURL Autodiscovery via Simple Weblog Plug-ins
For all of the above screenshots, Web browsers were configured to use JavaScript in one of two ways. First, a bookmarklet could be enabled in a browser toolbar that users can click whenever they see an 'OpenURL' icon, or simply as text, on any page they visit. Bookmarklets can be easily configured in this way for all major browsers on all major platforms. Alternatively, a browser extension (in this case, Greasemonkey [24] for Firefox) can be loaded with a slight variation on the bookmarklet script, and configured by default to execute the script automatically on all (or only user-specified) pages visited by the user. A benefit of this latter approach is that users need to do nothing once they have installed the extension and script; simply visiting pages will pop up appropriate resolver buttons whenever autodiscoverable OpenURLs are included on any page from any site anywhere on the Web.
Note how these examples demonstrate how simple and inexpensive publishing (and, in turn, following) appropriately routable OpenURL links could become with this model. Demonstration: Integration with Scholar's Box Figure 6 demonstrates an extension of the Scholar's Box toolkit for personal collections to support OpenURL autodiscovery [25][26]. In this example, the Scholar's Box has been used to export collected references directly into a weblog entry from the Scholar's Box itself.
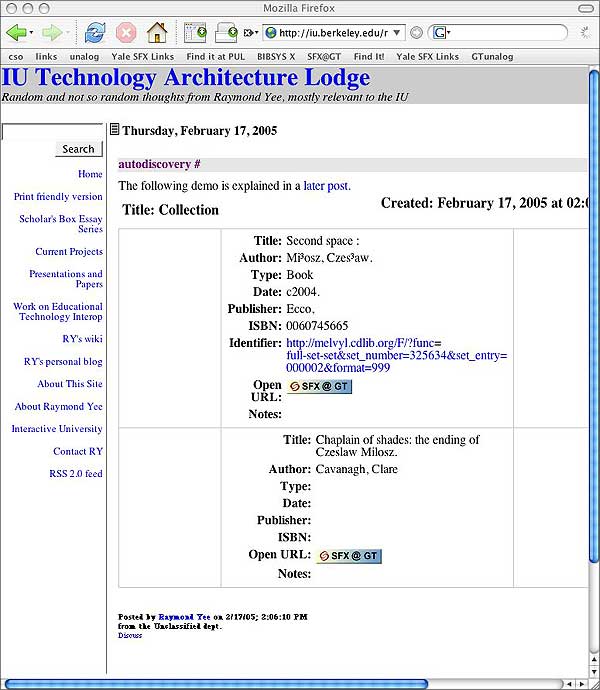
Figure 6: OpenURL Autodiscovery from Scholar's Box Export to Weblog
By exporting references matching our prototypical 'standard' pattern, the Scholar's Box demonstrates an important aspect of the full 'Gather, Create, Share' cycle: that newly shared materials can be easily gathered again by others. That is, the Scholar's Box user has 'gathered' the item (possibly from its original location), and then 'created' a weblog entry that itself 'shares' the citation again. People visiting this page could, in turn, 'gather' the cited resource for themselves, through their own resolver. Although they would be gathering a 'shared' copy of the citation (not the original), they are equally empowered to further 'create' and 'share' as they see fit. This way, every user involved can gather locally and share globally.
Demonstration: Integration with the WAG the Dog Web Localizer
Figures 7 and 8 demonstrate application of OpenURL autodiscovery within a Web localisation application. In Figure 7, Georgia Institute of Technology's WAG the Dog Web Localizer [27] has altered the output of Google Scholar to both insert local OpenURL links for the Georgia Tech community, and to check availability within Georgia Tech's holdings by querying the resolver inline before inserting the links at all.
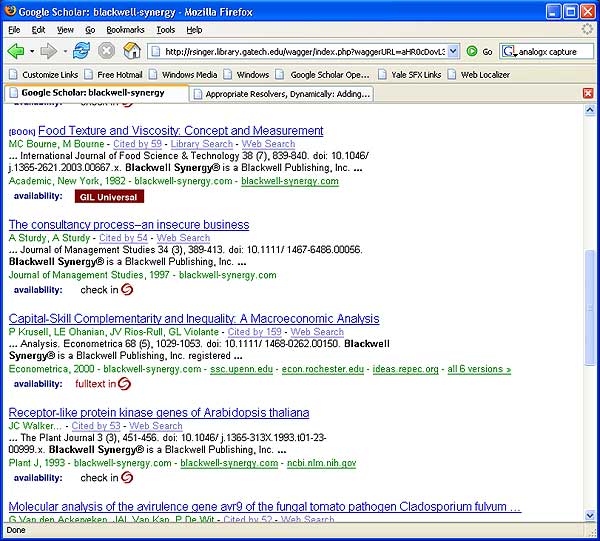
Figure 7: WAG the Dog Web Localizer at Georgia Tech and Google Scholar
Figure 8 further demonstrates the WAG the Dog Web Localizer leaving OpenURL autodiscovery tags in its wake, allowing localisation for any user. In this example, the Georgia Tech 'WAGged' page is then localised for a Yale user via a bookmarklet click. This might be useful for scholars from one institution while visiting another, and it might also be useful in letting collaborating researchers use links published at other institutions to connect to article full text or other services at their own institution.
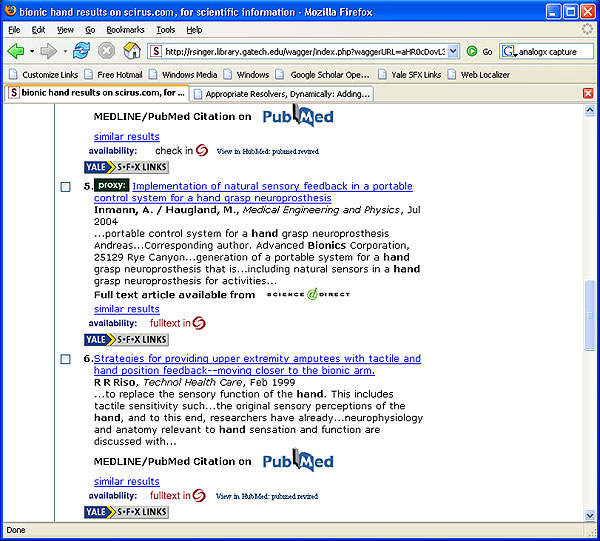
Figure 8: WAG the Dog Web Localizer at Georgia Tech and Yale, and Scirus
By knowing something about what the user is looking at, the Web Localizer can push other, similar services to the user wherever they are. The idea of advertising related resources is an especially useful side effect of being able to parse objects on the page, as links into those resources can be prepopulated with information from the OpenURL or other data from the page or about the site. This provides a new way to expose library collections and services in a contextually relevant manner, wherever users may be.
Adding a Layer on Top of OpenURL Autodiscovery
Consider that the RSS and OpenURL autodiscovery techniques involve two cooperating software tools: a client browser (or other application) that knows where to look for a certain kind of information, and a Web resource that specifies that exact kind of information. When the client application sees that information, it can offer additional functionality to its user; if that information is not present, the functionality is not offered. Either way, no additional information has passed between the two cooperating tools.
A more complex version might entail a similar first step, where a client finds information matching a known pattern in a page, and then operates on that information by either looking for more information elsewhere on the same page, or by sending one or more additional requests to the server (or some other resource, depending on the earlier information). We can imagine that this model might be useful in the kind of personal collection system environment provided by tools like the Scholar's Box, which try to 'gather' as much information about a collected item as possible from the item's original location. The Scholar's Box needs to be able to pull down as much 'trustworthy' metadata for an object at 'gather-time' as possible. Prototypes of Scholar's Box and similar efforts make heavy use of locally-available resources, and tend to have specific resource-to-resource conduits crafted for optimal transfer of information between systems, such as a direct (hard-coded) connection between a digital collection and a local catalogue. Stated as a general problem, collection tools like these need to be able to ask the question:
"For some resource in which a user is interested, what kinds of metadata records do you have, and may I have them please?"
Then, they must be able to follow through on the answers provided by collecting and managing those records.
Fortunately, the OAI-PMH can provide the answers we would need. If a site provided both a Web interface to content and a OAI-PMH interface for harvesting, simple hooks between the user interface and the OAI-PMH interface could allow Scholar's Box or similar tools to pull down metadata for a given item as needed, without any guesswork.
Take, for instance, a map from the United States Library of Congress American Memory site [28]. Note that the Memory server - which indeed does have a parallel OAI-PMH interface -- provides its items' digital identifiers on each item page (labelled "DIGITAL ID"). Unlike the simpler OpenURL autodiscovery examples above, Scholar's Box would need at least two pieces of information from the Memory page to 'collect' that map fully into a personal collection.
First, the map's "DIGITAL ID" would need to be encoded in some standard format. Because OpenURL supports local identifiers, the same link pattern we used before could also work here:
<a name='id=memoryid:g3732a.np000050' rel='alternate' title='OpenURL' />
This would provide critical information to a browser extension or other remote application like the Scholar's Box - the desired item's unique identifier within the system - in an agreed format.
Second, all content-rendering pages within the Memory site could also provide an HTML element like this:
<link rel='meta' type='application/xml' title='OAI-PMH 2.0'
href='http://memory.loc.gov/cgi-bin/oai2_0?' />
With just these two pieces of information - the object's local identifier, and the site's OAI-PMH service location - the Scholar's Box or any other client that knows to look for the one when it sees the other could discover and then harvest preferred-format metadata for this particular map.
Because there might be many separate objects of interest on any single page, and therefore a number of separate identifiers, great care would be needed to devise an agreed technique for associating the distinct identifiers with their objects within the information structure of the page. Assuming such a technique can be agreed, tools as simple as our prototype Web browser bookmarklets and extensions could also offer up additional user interface components highlighting the presence of robustly identified objects, and perhaps even a pre-processed 'right-click' menu of possible services based on the combination of the OpenURL and knowledge about the type of available metadata services. In a way, this potential kind of use of an OAI-PMH interface mirrors the kind of 'User Interface for OAI-PMH' described in a 2003 article [29]. In that article, public user interface front-ends are created dynamically from information inside an OAI-PMH repository. In the service described roughly here, access to data via OAI-PMH is dynamically provided from an existing public view of collections, not the other way around.
If it might be so easy to add OAI-PMH-backed metadata options, and embed OpenURL link information, many other pieces might be added into the mix. Quick access to parseable rights information might be manageable simply through OAI-PMH, for instance, and services like the aforementioned Pubmed could easily tie 'discoverable' pointers to their many Entrez services directly from their user interfaces.
Discussion and Next Steps
Much work has already gone into making specifications like WSDL (for Web service interface descriptions [30]) and UDDI [31] (for service directories) stable and scalable. As easily as we can imagine simple techniques for autodiscovery succeeding, we can also imagine that many service providers would want to deliver more robustly defined tiers of services via these widely known standards. The difference between industrial-strength standards like WSDL and UDDI and the autodiscovery examples discussed here is simplicity: anyone can add a weblog plugin and start posting OpenURLs into their weblog, but UDDI-advertised Web services require serious development. Perhaps each has its place, and indeed, providers choosing to implement a Web services approach could, for instance, also provide a user interface link into already-discoverable service interfaces. The Entrez tools behind Pubmed, and many nascent OCLC services, to take two already-mentioned examples, already provide WSDL documents and Web services. The only thing missing in those cases is tools for end-user-manageable connectivity between human and machine interfaces.
One concern not yet mentioned is that many potential casual users of techniques like OpenURL autodiscovery are not affiliated with an institution providing resolver services. It is likely that before OpenURLs can ever truly take off, some form of broadly usable resolver services for general use outside academia will be necessary. That might entail anything from a small number of very large resolvers smart enough to route users to vendor-partners, to a micro-resolver model wherein even individual user applications have OpenURL resolution services built-in. It is difficult to guess what might be necessary without more experience, but it is easy to see that without resolvers for everybody, OpenURL use will remain limited to scholarly environments.
The authors hope this article leads to discussion among OpenURL implementers regarding whether the ideas presented here are sound, and if so, how they might be best codified into a simple statement of best practices for wide publication. Additionally, we hope that information services which publish OpenURLs might consider opportunities to ensure the data they provide meets whatever additional recommendations might come out of any public discussions or further documents related to this work. Similarly, any institution publishing local collections might also consider these simple ways to provide discoverable OpenURL metadata within their own services to enable their local users or users anywhere else better to utilise their materials.
The authors also intend to continue exploring opportunities to integrate and test the techniques discussed here, and invite comment from all interested parties. We look forward to the expected availability of large-scale OpenURL resolver registry services and intend to expand our existing demonstration applications to make use of any such services when they become available.
Conclusion
The concrete examples presented above, and the more speculative discussion following the examples, perhaps represent a simplistic view of how to implement information services. Even so, at this point in the development of digital library services, we have too many standards and service models finding too few users. In the particular case of extending autodiscovery to OpenURLs and metadata, the rapid uptake of RSS autodiscovery indicates a strong market demand for simplistic implementations of extremely useful service integration techniques.
Because of this, we believe a new type of information resource optimisation is now needed to help fix the problem of insufficient integration. It is no longer sufficient to work only to improve human interfaces for usability and wayfinding, and, separately, to improve automated interfaces for harvesting and scalability. We now also need to design our services to accommodate the needs of both users and systems to move freely between human and automated interfaces. Because the information services we provide and manage make up only a small fraction of the many information communities in which our users participate, we now need to design for the likelihood that users enter our resources from a wide variety of directions: from search engines, from their friends' weblogs, from course pages, from sharing networks, and from hand-coded Web pages. Once users arrive at a resource we provide (however they got there), they might want to take some or all of that resource with them over into another of those environments, or have their computers (or ours) send it around to one or several other places on their behalf. Above all, we must find ways to help them do all of that with only one or two clicks.
To meet these expectations, we need to make our systems accommodate information pathways we cannot ourselves anticipate. Autodiscovery for OpenURLs and metadata might support some of those pathways, because the autodiscovery model has already successfully demonstrated the potential for a level of integration that would have been difficult to anticipate even a few years ago. Lorcan Dempsey of OCLC has referred to this technique of better preparing resources and services to be sewn together in new ways as 'intrastructure' (rather than 'infrastructure') [32]. The autodiscovery model provides one early pattern to follow on the way to building out library intrastructure, with which we can perhaps accomplish many kinds of integration at a very low marginal cost.
Authors' note: We would refer readers to a new proposal defining a convention for the use of "Latent OpenURLs" such as those discussed in this article [33]. This proposal arose from interest in the ideas and prototypes discussed above and in previous work, and is being developed collaboratively by a variety of interested parties. Please refer to the proposal for information about how to work with these techniques, and how to communicate with its developers.
References
- Hammond T., Hannay T., Lund B. "The Role of RSS in Science Publishing", D-Lib Magazine, 10(12): December 2004 http://www.dlib.org/dlib/december04/hammond/12hammond.html
- The Open Archives Initiative http://www.openarchives.org/
- SRW/SRU - Search/Retrieve Web Service http://www.loc.gov/z3950/agency/zing/srw/
- Metadata Encoding & Transmission Standard http://www.loc.gov/standards/mets/
- Metadata Object Description Schema http://www.loc.gov/standards/mods/
- Metadata Authority Description Schema http://www.loc.gov/standards/mads/
- The OpenURL Framework for Context-Sensitive Services http://www.niso.org/committees/committee_ax.html
- Apps, A., "The OpenURL and OpenURL Framework: Demystifying Link Resolution", Ariadne 38 January 2004 http://www.ariadne.ac.uk/issue38/apps-rpt/
- Van de Sompel, H., Beit-Arie, O., "Generalizing the OpenURL Framework beyond References to Scholarly Works: The Bison-Futé Model", D-Lib 7 (7/8) July 2001 http://www.dlib.org/dlib/july01/vandesompel/07vandesompel.html
- Powell, A., "OpenResolver: a Simple OpenURL Resolver", Ariadne 28 June 2001 http://www.ariadne.ac.uk/issue28/resolver/
- Chudnov, D., Frumkin, J., Weintraub, J., Wilcox, M., Yee, R., "Towards Library Groupware with Personalised Link Routing", Ariadne 40 July 2004 http://www.ariadne.ac.uk/issue40/chudnov/
- The OpenURL Router http://openurl.ac.uk/doc/
- Information Environment Service Registry http://iesr.ac.uk/
- Brack, V., Closier, A., "Developing the JISC Information Environment Service Registry", Ariadne 36 July 2003 http://www.ariadne.ac.uk/issue36/
- The OCKHAM Initiative Digital Library Registry http://ockham.org/registry.php
- Flecker, D., McLean, N., "Digital Library Content and Course Management Systems: Issues of Interoperation: Report of a study group", July 2004 http://www.diglib.org/pubs/cmsdl0407/
- IMS Global Learning Consortium http://www.imsglobal.org/
- Sakai Project http://www.sakaiproject.org/
- Pilgrim, M., "RSS auto-discovery", May 2002 http://diveintomark.org/archives/2002/05/30/rss_autodiscovery
- Ragget, D., Le Hors, A., Jacobs, I., editors, "HTML 4.01 Specification: Basic HTML data types: Link Types", December 24 1999 http://www.w3.org/TR/REC-html40/types.html#h-6.12
- Chudnov, D., "Appropriate Resolvers, Dynamically: Adding rel and title attributes to OpenURLs. A Prototype.", http://curtis.med.yale.edu/dchud/resolvable/
- CiteULike http://citeulike.org/
- Canary Database http://canarydatabase.org/
- Greasemonkey http://greasemonkey.mozdev.org/
- Functional and Technical Overview of the Scholar's Box http://iu.berkeley.edu/IU/SB
- Scholar's Box http://raymondyee.net/wiki/ScholarsBox
- The WAG the Dog Web Localizer http://rsinger.library.gatech.edu/localizer/localizer.html
- United States National Park Service, "Acadia National Park, Maine, official map and guide / National Park Service, U.S. Department of the Interior." 1989 rev. ed., Washington, D.C., http://hdl.loc.gov/loc.gmd/g3732a.np000050
- Van de Sompel, H., Young, J.A, Hickey, T.B., "Using the OAI-PMH ... Differently", D-Lib 9(7/8) July/August 2003, http://www.dlib.org/dlib/july03/young/07young.html
- Christensen, E., Curbera, F., Meredith, G., Weerawarana, S., editors, "Web Service Definition Language (WSDL) 1.1", March 15 2001 http://www.w3.org/TR/wsdl
- UDDI.org http://www.uddi.org/
- Dempsey, L., "Stitching services into user environments - intrastructure", December 9 2004 http://orweblog.oclc.org/archives/000505.html
- Hellman, E. et al. "Latent OpenURLs in HTML for Resource Autodiscovery, Localization and Personalization (draft)", online at
http://www.openly.com/openurlref/latent.html