How the Use of Standards Is Transforming Australian Digital Libraries
The National Library of Australia (NLA) has been able to achieve new business practices such as digitising its collections and hosting federated search services by exploiting recent standards including the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), handles for persistent identification, and metadata schemas for new types of content. Each instantiation of the OAI-PMH opens up new ways of creating and managing our digital libraries while making them more accessible for learning, teaching and research purposes. Using handles as the basis for managing the persistence of a large, digitised collection has allowed information to be identified and cited in many different ways. Standards have transformed, and continue to transform, the way in which the National Library conducts its core business of making its digital library collections available for all to use.
Although the National Library of Australia has always adhered to the use of standards such as MARC21 and AACR2 for the creation and management of bibliographic data [1], our adoption of newer Web-based protocols has allowed users distant from the Library to experience digital and digitised collections in virtual ways. The Library has been able to retain legacy system investments by surfacing rich metadata into new services. This process has encouraged the exploration of the ongoing suitability of metadata schemas, as well as contributing to the assessment of the need for new schemas.
The Library promotes the standards it uses with a comprehensive overview on its Web site providing links to more detailed documents which can act as guidelines for other service providers [2].
This article focuses specifically on the application of standards in three areas:
- the creation of national resource discovery services;
- the assignment of persistent identifiers to digital objects;
- the generation of metadata to support the management and discovery of academic research outputs.
National Resource Discovery
Under the imprimatur of its Australian National Bibliographic Database (NBD) [3], the Library has supported federated resource discovery for more than two decades. Australian libraries have contributed cataloguing and holdings records for finding and copying in a centralised framework since 1981. Even when these processes gradually changed to a hybrid model, where records were created on individual open access catalogues, the contribution to a central discovery point remained intact. There is still a commitment to sharing information at this national level.
The arrival of other metadata schemas such as the Dublin Core allowed the National Library to emulate the hybrid model for the discovery of digital objects. The Library first became interested in the Open Archives Initiative when its harvesting protocol was known as the Santa Fe convention [4]. However, it was not until the stable OAI-PMH version 1.1 became available that the Library implemented it, initially in the PictureAustralia service [5]. The service was able to move from a clunky http/HTML method of harvesting to the more streamlined use of the OAI-PMH. This decision enabled other cultural agencies such as state and regional libraries and museums to become familiar with its use. Australian university libraries and cultural institutions overseas are now also providing digitised images to the service [6].
Before using the OAI Protocol for Metadata Harvesting, complete Web harvesting for PictureAustralia took about 14 days every two months. Harvesting larger sites with around 200,000 metadata records took up to five days and was not completely reliable. Sometimes a harvest of these large sites would fail and have to be completely re-done. The PictureAustralia service was really only up to date six times per year.
After implementing OAI, a complete OAI harvest of the large sites took about 4 hours. Incremental OAI harvests take less than one minute. At present the Library uses a hybrid model where the larger sites which have OAI are incrementally harvested every day. The smaller sites are Web-harvested once per week. PictureAustralia is therefore completely up to date once a week, which represents an improvement in the currency of the more than one million records in the service.
Experience with the OAI-PMH and the use of the Online Computer Library Center (OCLC)'s OAICat software [7] with the Library's digital object repository opened up our digital libraries of cultural heritage materials for inclusion in international federated resource discovery services such as Google [8], OAIster [9] and the Research Library Group's Cultural Materials Initiative [10].
Use of the Protocol in open services, which are available 24 hours and 7 days a week, gives the National Library a solid platform from which to move to the next stage of new service development. The Library has been encouraging the university sector to work with OAI infrastructure by using a small prototype to harvest research outputs and collocate materials useful for research purposes [11]. This work is being progressed as part of the Australian Higher Education sector's ARROW Project [12]. The Library is developing a national discovery layer, which will harvest the metadata for all research outputs from individual institutional repositories and provide cross-searching services. Additional functionality is still being considered.
Persistent identification
One area where it has been difficult to obtain international agreement is in the establishment of a single Universal Resource Naming scheme for digital or digitised objects [13].
The Library considers persistent identification of digital objects to be a necessary part of managing a digital library, just as ISBN and International Standard Serial Number (ISSN) assignments are essential components of managing a print-based collection. Identification schemes for print-based objects such as books (ISBNs) or journals (ISSNs) or sheet music (International Standard Music Numbering - ISMNs) were tested, and in some cases were successfully redeployed as a component part of a digital identifier for digital materials, but they do not match requirements exactly for objects which do not emulate print forms.
The Library introduced a persistent identification scheme in 2001 to assign identifiers to objects in sub-collections, such as Web sites captured into the digital archive PANDORA [14]. Based on the Handle system, the scheme was extended to provide further intelligence for composite digitised objects such as manuscripts. For example, <collection id>-<collection no.>-<series no.>-<item no.>-<sequence no.>-< role code>-<generation code> becomes nla.ms-ms8822-001-0001-002-d for the file which is the display image of the second page of the first item in series 1 of the Mabo papers [15]. The Library has recently registered its persistence schemes in the Info-URI registry hosted by OCLC [16].
"Using persistent identifiers provides the ability to guarantee:
- long term citation of online documents;
- archiving digital materials;
- managing multiple copies, particularly at different locations;
- no ambiguity, in order to support rights management;
- transfer to new hardware and software platforms; and
- browser bookmarks." [17]
A persistent identifier scheme is also being used in the ARROW Project, which provides an additional commitment to the delivery of a top-quality service.
Metadata Principles
The National Library has worked with descriptive metadata standards such as MARC21 and AARC2 since the 1960s. But there has been a well-recognised controversy over the use of bibliographic standards in recent times. The return on investment in the metadata creation process has been challenged [18].
It is true that there has been an explosion in the amounts of information, in packaged or unpackaged form, which needs describing. There are simply not enough qualified professionals such as librarians and indexers available to create the necessary descriptions for subsequent discovery and management of information objects. Providers of tertiary-level information services have started to query this. The ARROW Project is exploring a combination of solutions for the creation of metadata, which will adhere to the following seven principles:
- A digital work instantiates the metadata and provides additional information about itself which does not need to be encoded. The Dublin Core metadata schema itself is an exemplar of this principle [19]. Bibliographic standards such as MARC21 needed to be extensive because the item being described is not available to the researcher in the first step of their researching process. Discovery and selection could only be satisfied by assessing the metadata. For digital works, while some metadata is necessary to save time while searching, for example to refine large results sets, further decision-making about the suitability of the material can be made by looking at the work itself. This principle is also being tested by the Australian Higher Education sector, and some early results have been made available by the Collaborative Online Learning and Information Services (COLIS) Project [20].
- Metadata can be used to integrate access to all research output including research mid-process such as scientific analysis and musical composition, not just an end-product of that research. The eBank UK Project is developing a holistic approach to metadata creation which must support 'the perceived hierarchy of data and metadata from raw data up to "published" results' [21]. Sharing a common schema for harvesting by service providers will achieve integration of access both intra-institutionally and across the higher education sector. This principle has been proven by the National Bibliographic Database.
- The metadata schema needs to be cost-effective to encourage creation. The return on investment of the creation process must be convincing in order to encourage ongoing, consistent practice. The OAI Protocol for Metadata Harvesting itself is an example of this principle. Originally designed to operate in the academic sector, the Protocol was quickly adapted by a broader range of agencies because of its simplicity and efficiency.
- If someone makes the decision to create metadata, then the work is worthy. The investment in the automated software tools made by the Online Computer Library Center (OCLC) Office of Research to exploit pre-existing metadata illustrates this principle. A range of new tools being developed by OCLC illustrate its commitment to the creative use of metadata, which will further extend the availability and value of both unpublished and published research outputs [22].
- The process of metadata creation is a commitment to quality. The University of British Columbia's Public Knowledge Project (PKP) [23] provides a test case for quality metadata. While the Dublin Core schema has been chosen as a baseline, the metadata profile created by the PKP is a rich instantiation of it.
- For metadata to serve the purpose of future resource discovery, enhanced metadata is required to ensure the longevity of resources. One way of achieving enhanced metadata, without placing an extra burden on creators, is by generating it. The National Library of New Zealand has developed a suite of tools to capture pertinent metadata at the time of ingest of a digital object into its repository [24]. Similarly, it is possible for the metadata creation tool used during deposit and update to capture system information from these processes. The persistent identifier(s) of a digital object and its component parts are a specific example of enhanced metadata.
- Metadata creation guidelines can change to reflect the current working environment, for example, the deployment of the Australian Standard Research Classification list as a thesaurus for subject terms [25] to describe the topics of Australian research output. An internationally recognised thesaurus would be preferred, but remains a contentious issue. Nevertheless, guidelines need to be reviewed and refreshed to ensure they remain relevant to as many services as possible.
The working environment will also dictate in part who creates the metadata. The ARROW Project is investigating whether a shared approach will deliver the best result. This concept has already been explored to a certain extent for the UK Higher Education sector by the ePrints UK service [26].
Metadata Workflows
The creation/addition of metadata in any working environment is not necessarily undertaken in the implied linear order of the diagram below (provided by UKOLN) - it should be an iterative process - but it does exemplify how multiple roles in the metadata creation process are possible. The new business cases for the management of research outputs, postulated by the establishment of individual institutional repositories, allows for metadata workflows to be engineered afresh. They are not restricted by pre-existing data conditions often imposed by legacy metadata [27].
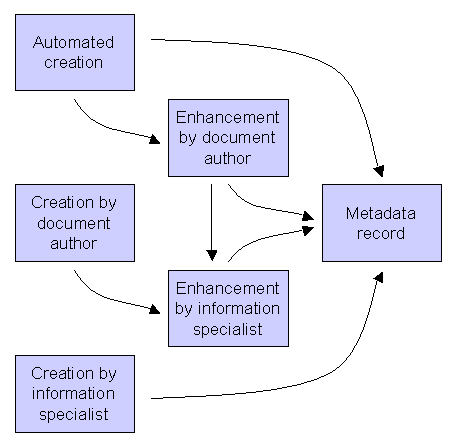
Figure 1: Metadata creation workflow
(Diagram Source: Improving the Quality of Metadata in Eprint Archives, Marieke Guy, Andy Powell and Michael Day, Ariadne Issue 38 [26]). The ARROW Project is keen to explore how workflows for metadata creation can be transformed by this approach. Automated approaches may require review combined with enhancement.
Information specialists including librarians and indexers can add metadata from rich schemes such as Library of Congress Subject Headings after the creator of the work creates a skeleton metadata record.
Metadata, the bread and butter of cataloguing services such as the Australian National Bibliographic Database, can attract a dual responsibility and continue to facilitate the sharing of information by libraries for the benefit of everyone else. A shared approach provides a response to the concerns expressed recently by Tony Hey, Director of the e-Science Project [28]. Capturing the metadata, using a combination of people with a stake in the longevity of their work and automated software is the first step in changing the way digital objects, the foundation stone of digital libraries, can be identified, captured and managed in perpetuity. What better way to transform services to become our digital libraries of the future?
Acknowledgements
The author is grateful to colleagues Jasmine Cameron, Assistant Director-General and Tony Boston, Director Digital Services, both of the National Library of Australia, for their assistance in reviewing this article.
References
All URLs accessed 14 April 2004
- Machine Readable Cataloguing (MARC) Standards http://www.loc.gov/marc/ ; Anglo-American Cataloguing Rules (AACR) http://www.collectionscanada.ca/jsc/docs.html
- National Library Standards Activities http://www.nla.gov.au/services/standards.html
- The National Bibliographic Database http://www.nla.gov.au/libraries/resource/nbd.html
- The Santa Fe convention http://www.openarchives.org/meetings/SantaFe1999/sfc_entry.htm
- How PictureAustralia works http://www.nla.gov.au/nla/staffpaper/2003/boston1.html
- Scottish Cultural Resources Access Network (SCRAN), http://www.pictureaustralia.org/scran.html; the National Library of New Zealand, http://www.pictureaustralia.org/nlnz.html
- National Library of Australia Digital Object Repository http://www.nla.gov.au/digicoll/oai/
- Simply seeding search engines http://www.nla.gov.au/nla/staffpaper/2003/dcampbell2.html
- OAIster; http://oaister.umdl.umich.edu/o/oaister/
- Cultural Materials Initiative http://culturalmaterials.rlg.org/
- Resource Discovery Service http://www.nla.gov.au/rds/
- the ARROW (Australian Research Resources Online to the World) Project http://www.arrow.edu.au The ARROW Project is sponsored as part of the Commonwealth Government's Backing Australia's Ability http://backingaus.innovation.gov.au/
- Persistent Identification Systems, Part 1 : Background http://www.nla.gov.au/initiatives/persistence/PIpart1.html
- Persistent Identifiers and the NLA http://www.nla.gov.au/initiatives/persistence/PIpart2.html ; Preserving and Accessing Networked Documentary Resources of Australia (PANDORA), http://pandora.nla.gov.au
- The Papers of Edward Koiki Mabo (1936-1992) are described in full http://nla.gov.au/nla.ms-ms8822 The persistent identifier is explained at http://www.nla.gov.au/initiatives/nlapi.html
- "Info" URI scheme http://info-uri.info/registry/
- Persistent Identification Systems, Part 3: The Achievement of Persistent Access to Resources, National Library of Australia http://www.nla.gov.au/initiatives/persistence/PIpart3.html
- To Meta-tag or not to meta-tag, A skeptical view http://www.melcoe.mq.edu.au/documents/MD.Debate.Dalziel.ppt
- Dublin Core Metadata Element Set, Version 1.1: Reference Description http://dublincore.org/documents/dces/
- Key Findings, University of Tasmania consortium; http://www.melcoe.mq.edu.au/projects/Key%20Findings.pdf
- eBank UK http://www.ukoln.ac.uk/projects/ebank-uk/
- OCLC Research Works http://www.oclc.org/research/researchworks/default.htm
- Public Knowledge Project http://www.pkp.ubc.ca/harvester/
- National Library of New Zealand Preservation Metadata Extraction Tool http://www.natlib.govt.nz/files/Project%20Description_v3-final.pdf
- This scheme is used exclusively by the Australian Higher Education sector. Its maintenance agency is the Australian Bureau of Statistics. A copy is provided by the University of Queensland http://eprint.uq.edu.au/view/subjects/subjects.html
- Improving the Quality of Metadata in Eprint Archives, Marieke Guy, Andy Powell and Michael Day, January 2004, Ariadne Issue 38 http://www.ariadne.ac.uk/issue38/guy/
- MusicAustralia: Experiments with DC.Relation http://www.nla.gov.au/nla/staffpaper/2003/ayres1.html
- Why engage with e-Science
http://www.cilip.org.uk/publications/updatemagazine/archive/archive2004/march/update0403b.htm